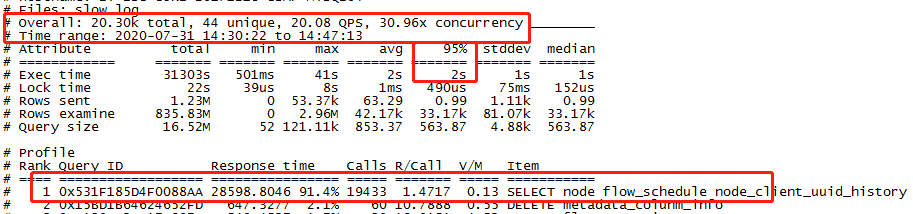
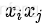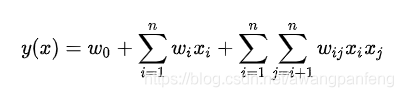背景
全球汽车行业有两个公认的汽车自动驾驶技术分级标准,二者的定级差异不大:
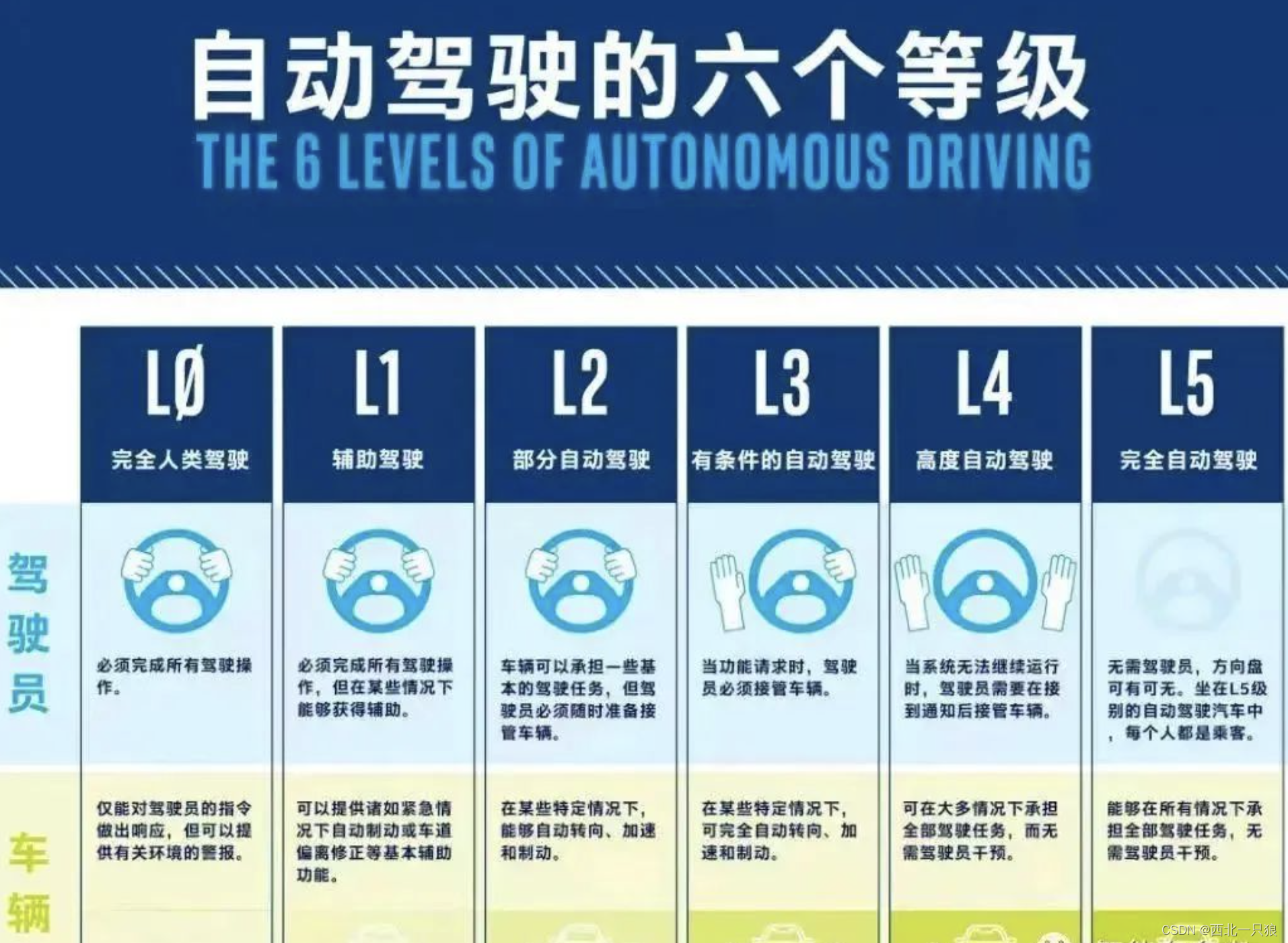
L0级:自动驾驶仅能提供警告和瞬时辅助。值得注意的是,主动刹车、盲点监测、车道偏离预警和车身稳定系统都属于L0级别的自动驾驶
L1级:辅助驾驶,能够帮助驾驶员完成某些驾驶任务,且只能帮助完成一项驾驶操作。驾驶员需要监控驾驶环境并准备随时接管。代表性技术应用有:车道保持系统,定速巡航系统。
L2级:部分自动化,可以同时自动进行加减速和转向的操作,也意味着自适应巡航功能和车道保持辅助系统可以同时工作。目前很多豪华车辆搭载的就为这一级别自动驾驶。但驾驶员仍需要将双手双脚预备在方向盘及制动踏板上随时待命。
L3级:条件自动化,车辆在特定环境中可以实现自动加减速和转向,不需要驾驶者的操作。驾驶员可以不监控车身周边环境,但要随时准备接管车辆,以应对自动驾驶处理不了的路况情况。这一代奥迪A8L就搭载了L3级别的自动驾驶技术,驾驶感受很是优异。不过在其之前,沃尔沃和特斯拉就已经实现了L3级别自动驾驶技术。
L4级:高度自动化,可以实现驾驶全程不需要驾驶员,但是会有限制条件,例如限制车辆车速不能超过一定值,且驾驶区域相对固定,实现L4级别自动驾驶后,已经可以不需要安装刹车和油门踏板了。
L5级:完全自动化,完全自适应驾驶,适应任何驾驶场景。但是涉及到法律、高科技突破等限制,目前还需要进一步深入研发,对应的产品目前还没有实现。
奔驰L3级自动驾驶系统,美国获批使用了。在众多汽车主机厂中,奔驰是美国史上第一个、而且还是仅此一家。有了这套系统,司机可以脱手驾驶,一边开车一边开小差纵情网上冲浪,出了事故也是奔驰的责任。
而且需要注意的是,你可以把头和眼睛侧向一边,但Drive Pilot必须要能够通过摄像头监测到你的脸。一旦你的脸被其他物体遮挡了,系统就会自动退出。
除此之外,奔驰官方甚至将Drive Pilot自动泊车功能直接上升到L4级别,据称可以实现完全无人场景下的自动泊车,包括自动寻找车位、规划路线、主动断电等功能,都已经在量产车上实现。
特斯拉想要的是L4-L5级自动驾驶,L3级是留给蠢蛋的