背景
全球汽车行业有两个公认的汽车自动驾驶技术分级标准,二者的定级差异不大:
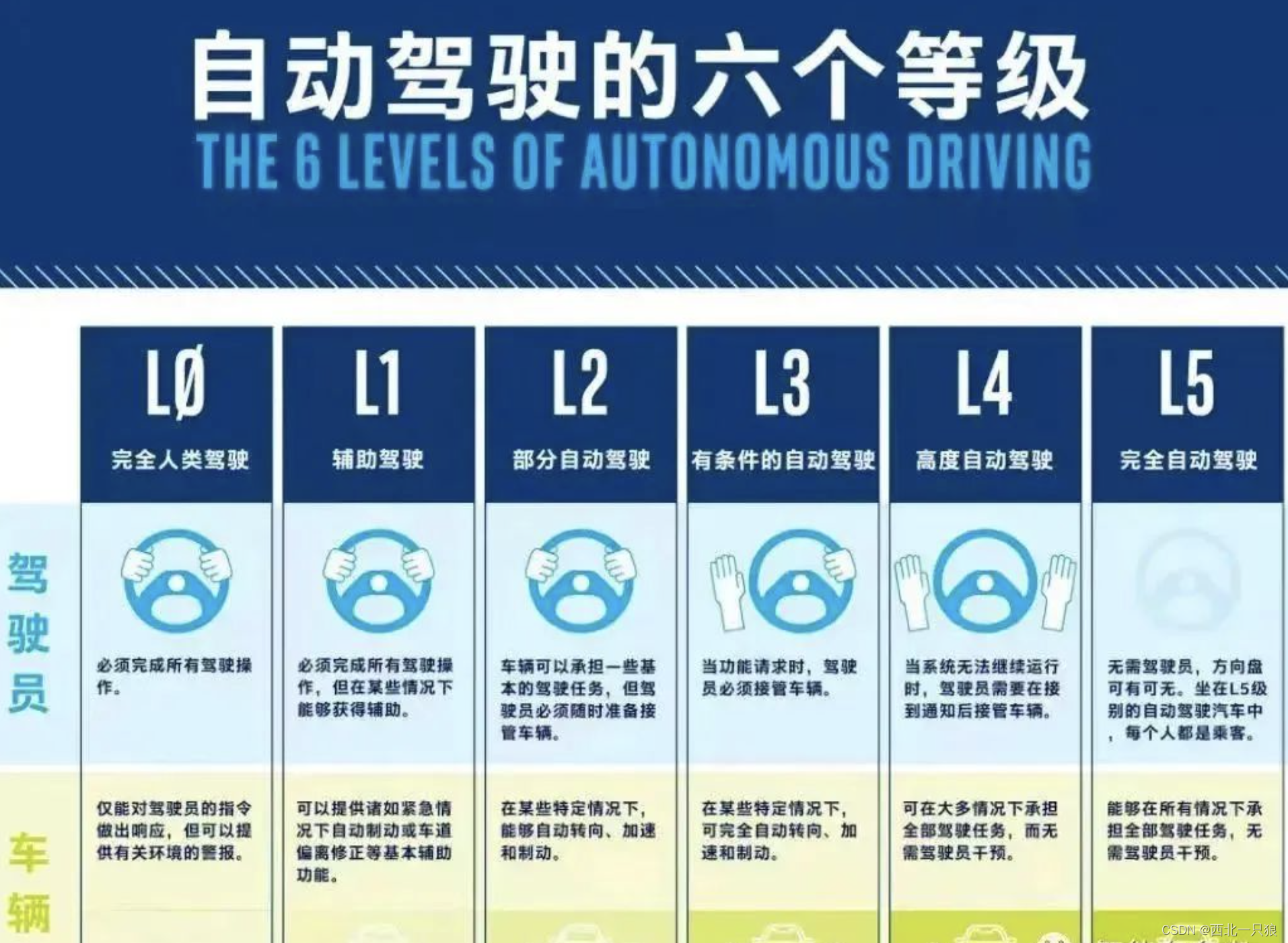
L0级:自动驾驶仅能提供警告和瞬时辅助。值得注意的是,主动刹车、盲点监测、车道偏离预警和车身稳定系统都属于L0级别的自动驾驶
L1级:辅助驾驶,能够帮助驾驶员完成某些驾驶任务,且只能帮助完成一项驾驶操作。驾驶员需要监控驾驶环境并准备随时接管。代表性技术应用有:车道保持系统,定速巡航系统。
L2级:部分自动化,可以同时自动进行加减速和转向的操作,也意味着自适应巡航功能和车道保持辅助系统可以同时工作。目前很多豪华车辆搭载的就为这一级别自动驾驶。但驾驶员仍需要将双手双脚预备在方向盘及制动踏板上随时待命。
L3级:条件自动化,车辆在特定环境中可以实现自动加减速和转向,不需要驾驶者的操作。驾驶员可以不监控车身周边环境,但要随时准备接管车辆,以应对自动驾驶处理不了的路况情况。这一代奥迪A8L就搭载了L3级别的自动驾驶技术,驾驶感受很是优异。不过在其之前,沃尔沃和特斯拉就已经实现了L3级别自动驾驶技术。
L4级:高度自动化,可以实现驾驶全程不需要驾驶员,但是会有限制条件,例如限制车辆车速不能超过一定值,且驾驶区域相对固定,实现L4级别自动驾驶后,已经可以不需要安装刹车和油门踏板了。
L5级:完全自动化,完全自适应驾驶,适应任何驾驶场景。但是涉及到法律、高科技突破等限制,目前还需要进一步深入研发,对应的产品目前还没有实现。
奔驰L3级自动驾驶系统,美国获批使用了。在众多汽车主机厂中,奔驰是美国史上第一个、而且还是仅此一家。有了这套系统,司机可以脱手驾驶,一边开车一边开小差纵情网上冲浪,出了事故也是奔驰的责任。
而且需要注意的是,你可以把头和眼睛侧向一边,但Drive Pilot必须要能够通过摄像头监测到你的脸。一旦你的脸被其他物体遮挡了,系统就会自动退出。
除此之外,奔驰官方甚至将Drive Pilot自动泊车功能直接上升到L4级别,据称可以实现完全无人场景下的自动泊车,包括自动寻找车位、规划路线、主动断电等功能,都已经在量产车上实现。
特斯拉想要的是L4-L5级自动驾驶,L3级是留给蠢蛋的
数据重要性
数据有助于迭代算法,算法质量是自动驾驶企业的核心竞争力。用户数据对于改造自动驾驶系统极其重要。自动驾驶的过程中有一类发生概率不高的罕见场景,这类场景被叫做 corner case。若感知系统遇到了 corner case 则会带来严重的安全隐患。例如前几年发生的特斯拉的 Autopilot 没有识别出正在横穿的白色大卡车,直接从侧面撞上去,导致车主死亡;2022 年 4 月小鹏在开启自动驾驶的过程中撞上了侧翻在路中间的车辆。
此类问题的解决办法只有一个,便是由车企牵头收集真实数据,同时在自动驾驶计算平台上模拟出更多相似的环境,让系统学习以便下次更好地处理。一个典型的例子便是特斯拉的影子模式:通过与人类驾驶员行为进行比对,找出潜在的cornercases。而后对这些场景进行标注,并加入至训练集中。
相应的,车企需要建立数据处理流程,以便搜集上来的真实数据可以用于模型迭代,同时迭代后的模型可以实装到真实量产车上。同时为了大规模地让机器学习cornercase,在获取一个cornercase 后还会针对这一cornercase 遇到的问题进行大规模模拟,推导出更多的cornercases 系统学习。
算法框架
自动驾驶算法技术框架核心分为环境感知、决策规划、控制执行三部分。
- 环境感知:将传感器数据转换成车辆所处场景的机器语言,具体可以包括:物体检测、识别跟踪、环境建模、运动估计等;
- 决策规划:基于感知算法输出结果,给出最终行为动作指令,包括行为决策(车辆跟随、停止和超车)、动作决策(汽车转向、速度等)、路径规划等;
- 控制执行:在决策层的输出结果下,调动底层模块,向油门、刹车等核心控制部件发出指令,推动车辆按照规划线路行驶。
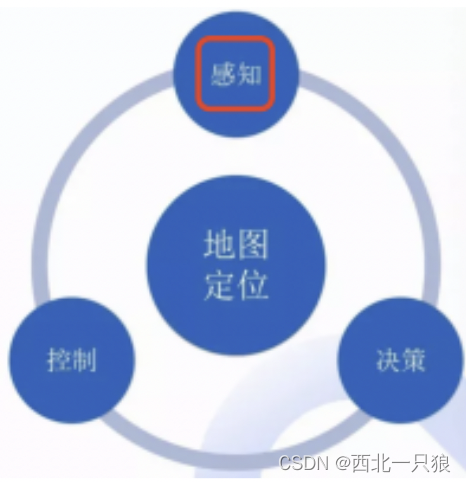
以Apollo为例,参考各个核心模块的实现:
环境感知
主要包括视觉感知、激光雷达感知与感知融合能力。视觉感知算法在 Apollo 平台上主要有 3 个应用场景,分别是红绿灯检测、车道线检测、基于摄像头的障碍物检测。
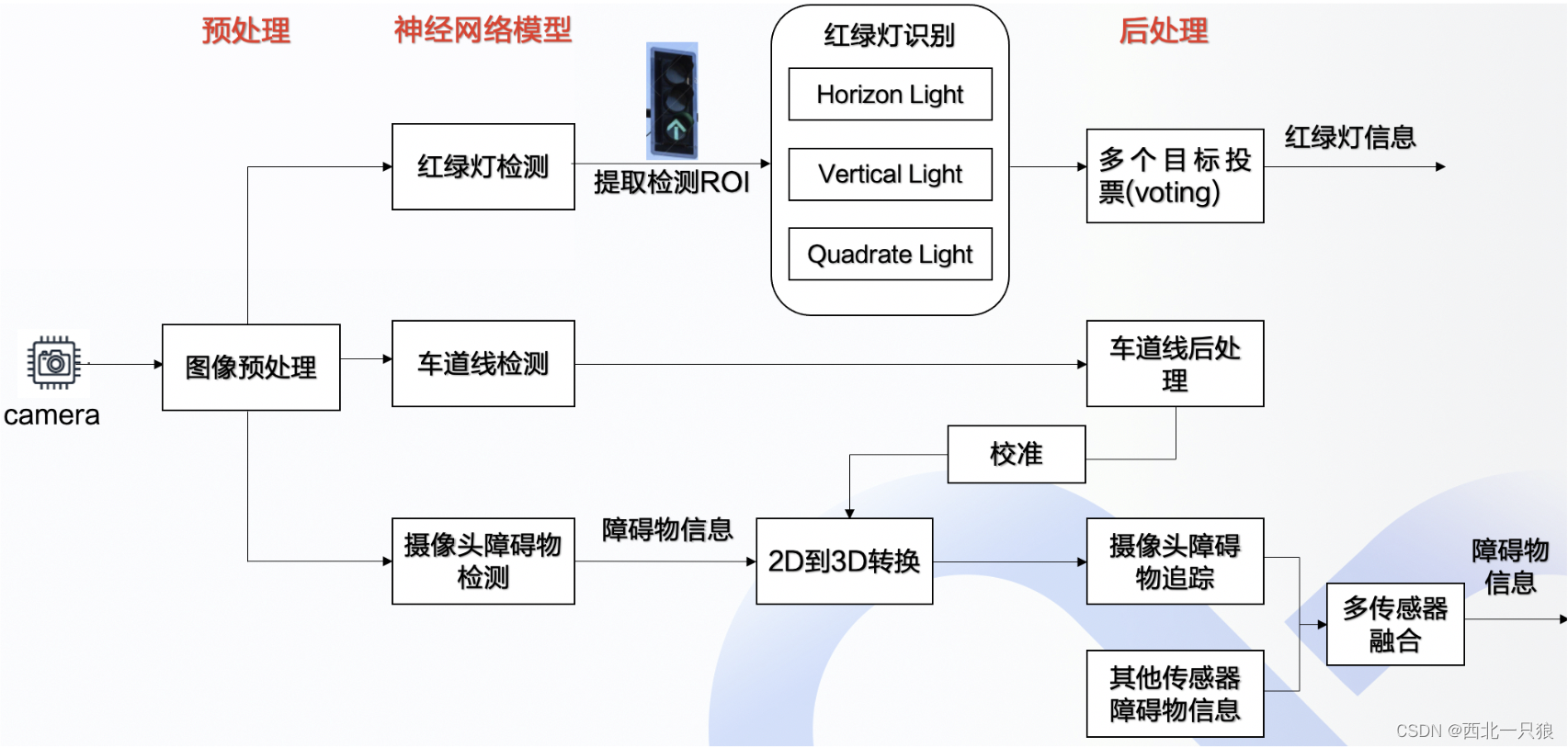
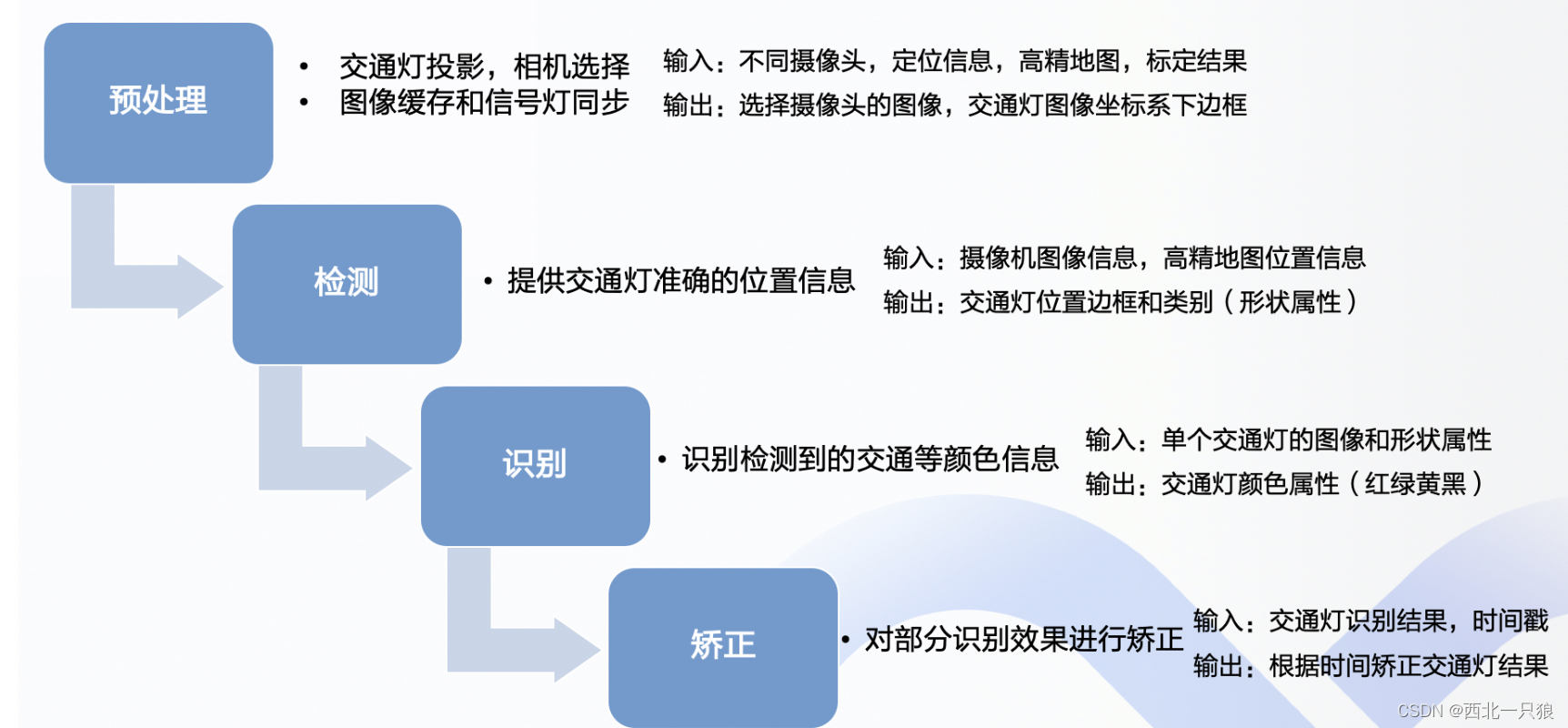
红绿灯检测模块的主要作用是检测当前路况下在摄像头的视觉范围内的红绿灯的状态,这是一个典型的目标检测任务(会借助高精地图给出的的信息预先从相机图像中将包含红绿灯区域的大致位置取出来)。
车道线检测模块当作分割问题,在图像中寻求对于语义上车道线存在位置的检测,即使它是模糊的、被光照影响的、甚至是完全被遮挡的,我们都希望能将它检测出来。
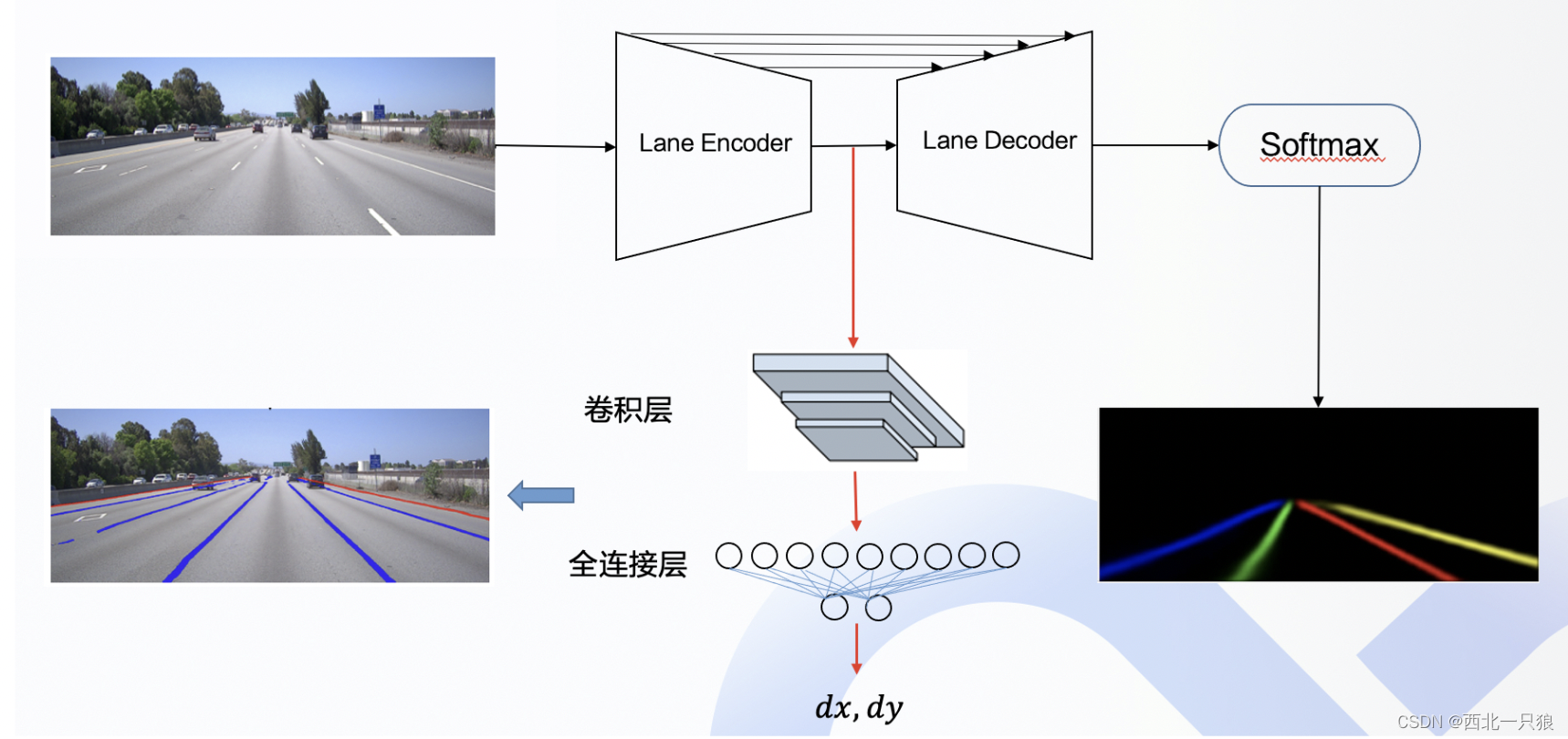
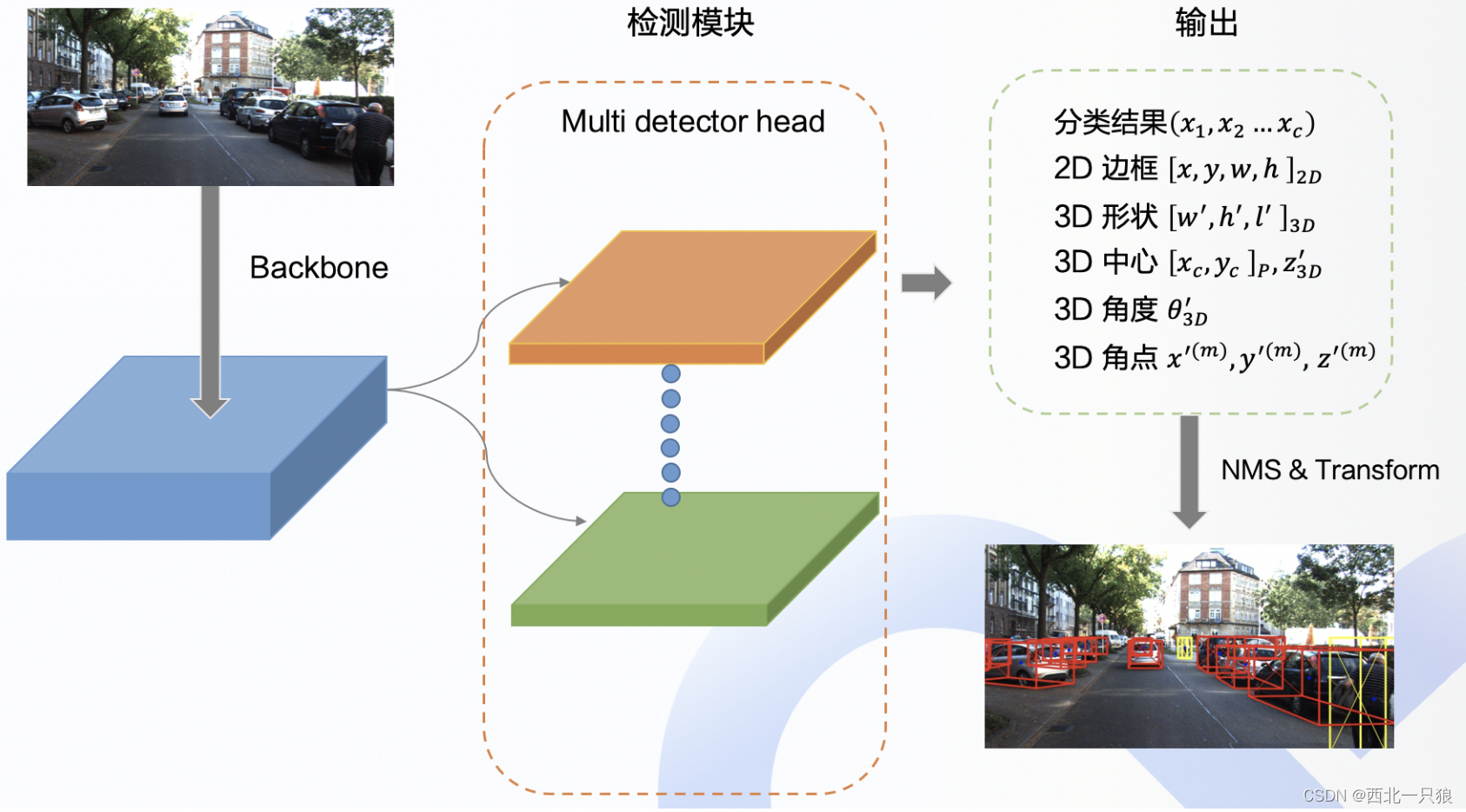
障碍物检测部分采用的是基于单目视觉的障碍物检测算法,根据相机获取的图像得到障碍的类别和位置信息。使用 7 个变量来表示 3D 边框,分别是物体的长宽高,物体的位置 x,y,z 以及物体的旋转角度 θ。
常用的感知传感器包括激光雷达、摄像头、毫米波雷达等,激光雷达传感器具备准确的障碍物定位能力。
激光雷达感知模块接受来自激光雷达驱动的点云信息,利用这些点云信息进行障碍物的检测以及跟踪,得到的结果会被输出到感知融合模块进行下一步处理。

激光雷达感知模块接收到点云数据之后,通过高精度地图 ROI(The Region of Interest)过滤器过滤 ROI 之外的点云,去除背景对象,例如:路边建筑物、树木等,过滤后的点云数据通过障碍物检测深度学习模型进行 3D 障碍物的检测和分类,然后对得到的障碍物进行跟踪,最终得到障碍物的形状、位置、类别、速度等信息。
Apollo 使用深度卷积神经网络对障碍物进行精确检测和分割。Apollo CNN 分割检测算法包括以下四个部分:
- 通道特征提取
- 基于 CNN 的障碍物预测
- 障碍物聚类
- 后处理
感知融合能力,多传感器融合是一个重要的环节,并且也是感知的最后环节。
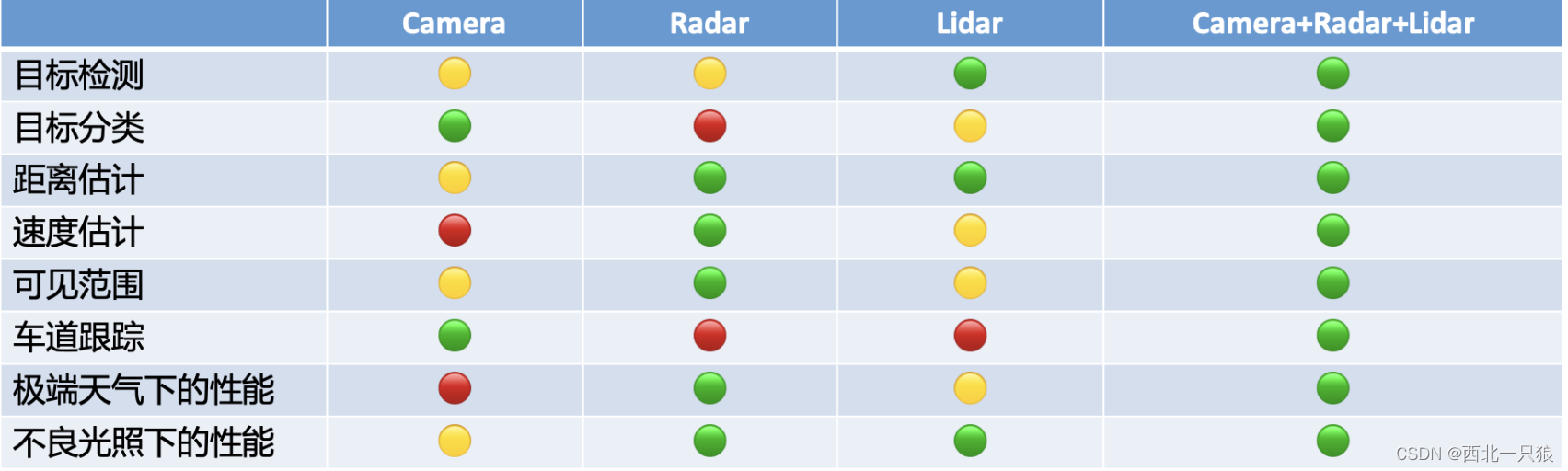
下图表示了摄像头(Camera)、毫米波雷达(Radar)和激光雷达(Lidar)传感器在不同任务和不同条件下的性能。其中,
- 摄像头:对于分类任务尤其准确,
- 毫米波雷达:在穿透性、距离估计和极端天气抗干扰性具有卓越的性能,
- 激光雷达:擅长目标检测任务。
如果能有效将三种传感器进行融合感知,就能在各种情况下都能达到优良的性能。
还有其他类型的感知模型,比如驾驶行为感知模型,能够应用于超车、转向、换道等典型驾驶行为的感知。同时提出了网联环境下换道、超车、转向意图识别模型,能够较好地对驾驶行为进行短期准确预测。
决策规划
规划模块的主要作用是结合障碍物、地图定位以及导航信息为自动驾驶车辆规划一条运动轨迹,这条轨迹由若干轨迹点组成,每个轨迹点均包含了位置坐标、速度、加速度、加加速度、相对时间等信息。
Apollo 规划模块功能的实现是基于场景实现的,针对不同的场景,规划模块通过一系列独立的 任务(task) 组合来完成轨迹的规划。开发者可以根据自己的使用需求,调整 apollo/modules/planning/conf/scenario/ 下的配置文件,调配任务组合实现自己的规划要求
Apollo 规划架构示意图如上,其中部分重要模块如下:
- 状态机(Apollo FSM(Finite State Machine)):一个有限状态机,结合导航、环境等信息确定自动驾驶车辆的驾驶场景
- 规划分发器(Planning Dispatcher):根据状态机与车辆相关信息,调用合适当前场景的规划器
- 规划器(Planner):结合上游模块信息,通过一系列的任务组合,完成自动驾驶车辆的轨迹规划
- 决策器 & 优化器(Deciders & Optimizers):一组实现决策和优化任务的 task 集合。优化器用于优化车辆的轨迹和速度。决策器则基于规则,确定自动驾驶车辆何时换车道、何时停车、何时蠕行(慢速行进)或蠕行何时完成等驾驶行为。
预测模块通过障碍物的历史状态信息,来预测障碍物的未来轨迹。感知模块作为预测模块的上游,提供障碍物的位置、朝向、速度、加速度等信息,预测模块根据这些信息,给出障碍物未来的预测轨迹,供下游规划模块进行自车轨迹的规划。
控制执行
控制模块是整个自动驾驶软件系统中的执行环节,控制模块的目标是基于规划模块输出的目标轨迹和定位模块输出的车辆状态生成方向盘、油门、刹车控制命令,并通过 canbus 模块给车辆底层执行器。
简单而言,就是告诉车辆该打多大方向盘、多大的油门开度、多大的刹车制动力。
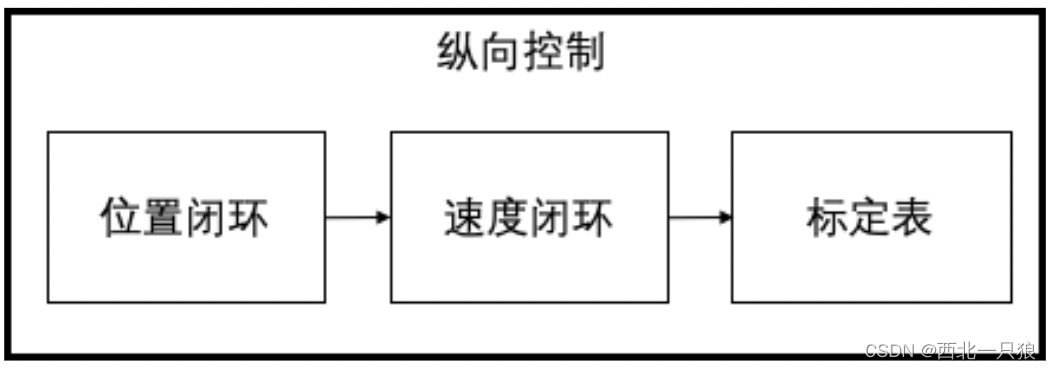
Apollo控制模块由两个子模块组成:横向控制模块和纵向控制模块。横向控制根据规划模块的轨迹生成方向盘指令。
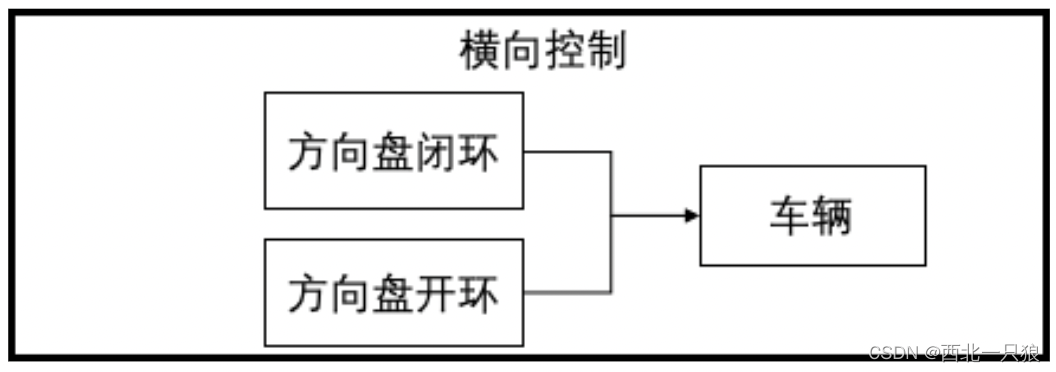
纵向模块根据规划模块的轨迹生成油门、刹车指令。
强化学习自动驾驶控制
可以认为Q-learnin是目前使用最广泛的强化学习算法,然而Q-learning一般基于表格设置,只能用于解决较低维度、离散的状态/动作空间的强化学习问题。将深度神经网络引入Q-learning,诞生了DQN(deep Q network)算法。深度学习具有强大的特征提取能力,这使得强化学习具备了直接从高维像素级别的状态空间提取特征并进行训练的能力。引入了深度学习以后的强化学习称为深度强化学习,其中深度神经网络可以作为强化学习中的策略函数、值函数或Q函数的逼近器。DQN算法在很多电子游戏中达到了人类专家级别的表现。DQN虽然解决了高维度状态空间的问题,但是仍然只能处理离散的、低维度动作空间的问题。然而实际的控制任务,尤其是自动驾驶任务,往往具有连续的、高维度的动作空间。解决方法之一是将动作空间离散化。然而,动作的数目随着自由度的增加而呈指数增长,而DQN难以在巨大的动作空间下进行有效的探索和训练。Lillicrap等人提出了深度确定性策略梯度(deep deterministic policy gradient,DDPG)算法,成功实现了连续状态和动作空间下的强化学习问题。该算法将DQN和Actor-Critic算法相结合,使用深度神经网络来逼近值函数和策略函数,其中值函数通过贝尔曼方程更新,而策略函数则通过梯度下降进行更新。然而DDPG算法具有较高的参数脆性,其超参数往往必须针对不同的问题进行仔细设置才能获得良好的训练结果。
2018年Haarnoja等人为了解决强化学习的高样本复杂性和超参数的脆性,并提高训练的稳定性,提出了SAC(soft actor-critic)方法。该方法将最大熵的概念引入强化学习,并超过了DDPG方法的效率和最终性能。
基于 DDPG 算法的自动驾驶策略学习过程示意图如下所示:
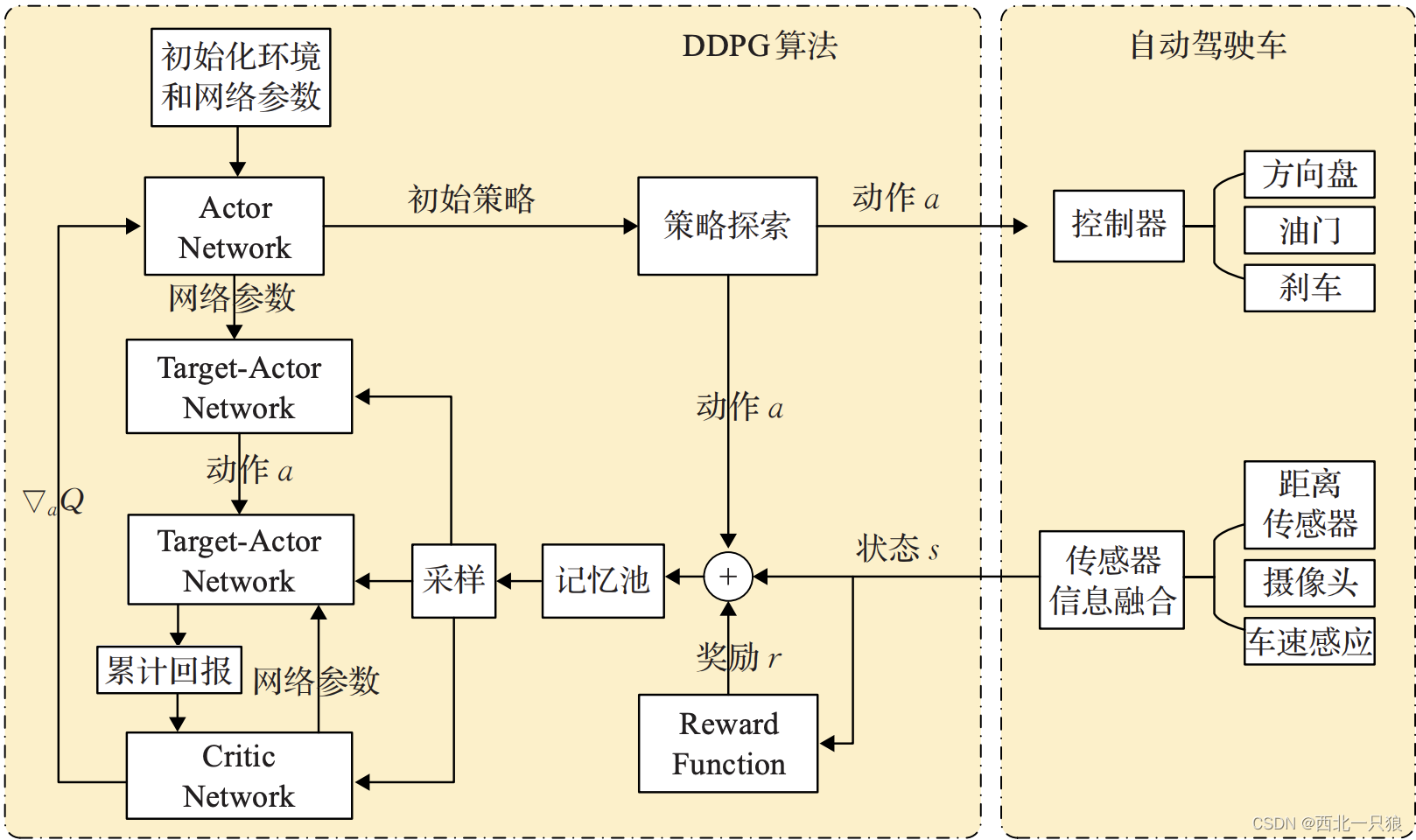
该算法通过 Actor网络产生驾驶策略,加入探索噪声后送入自动驾驶汽车执行,通过传感器系统融合后得到状态信息,并通过设计的回报函数计算当前回报值。算法将训练得到的状态-动作-下一状态-回报值 (st ,at ,rt ,st + 1) 存入经验缓存池,随机抽取经验,通过梯度下降法训练神经网络。
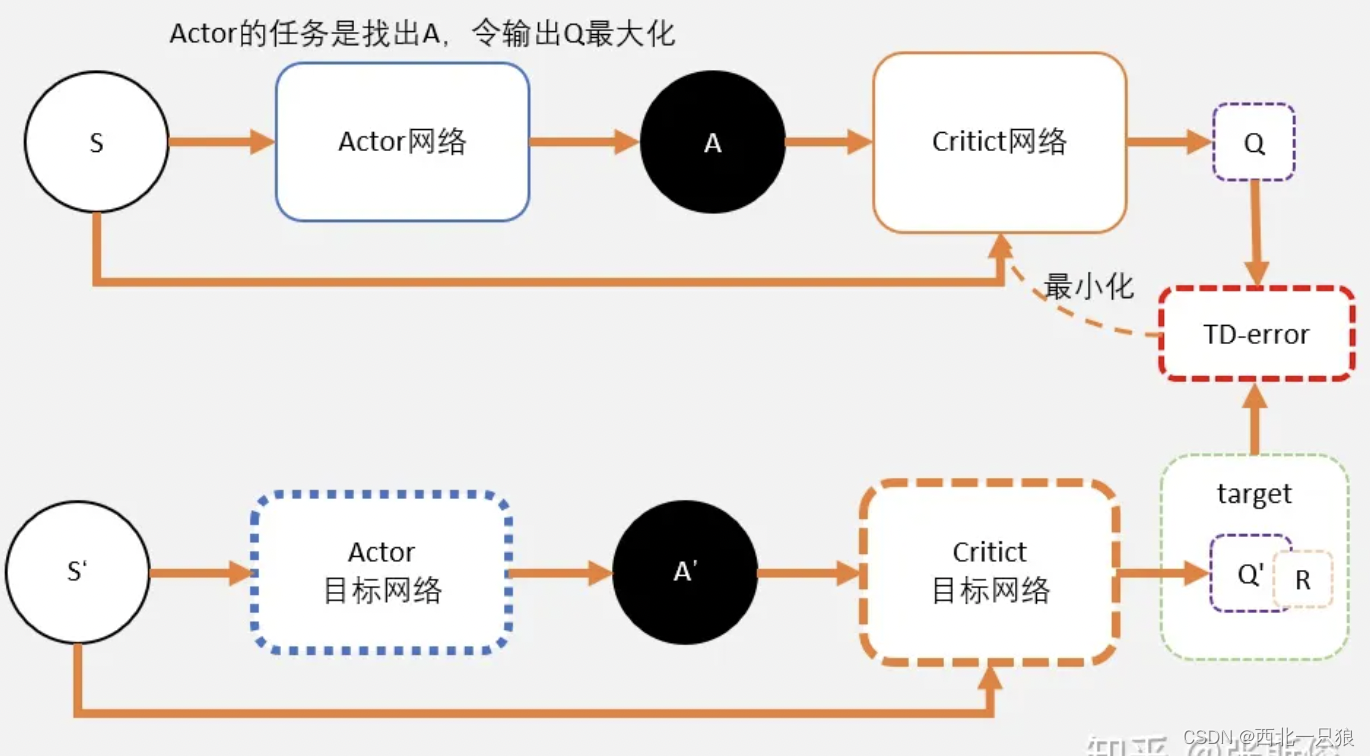
Actor-Critic 方法是建立 Actor 和 Critic 两个网络, Actor网络用于产生当前策略,Critic网络用于评判当前状态下策略的优劣。为提高训练的稳定性,引入TargetActor网络和Target-Critic网络。训练前,Target-Actor与 Actor以及 Target-Critic与 Critic的网络结构以及参数完 全相同。实做的时候,我们需要4个网络。actor, critic, Actor_target, cirtic_target参考:
Tensorflow给出的强化学习算法示例代码,DDPG算法核心实现:
1 | class DDPG(object): |
核心训练流程:
1 | #用DDPG算法 |
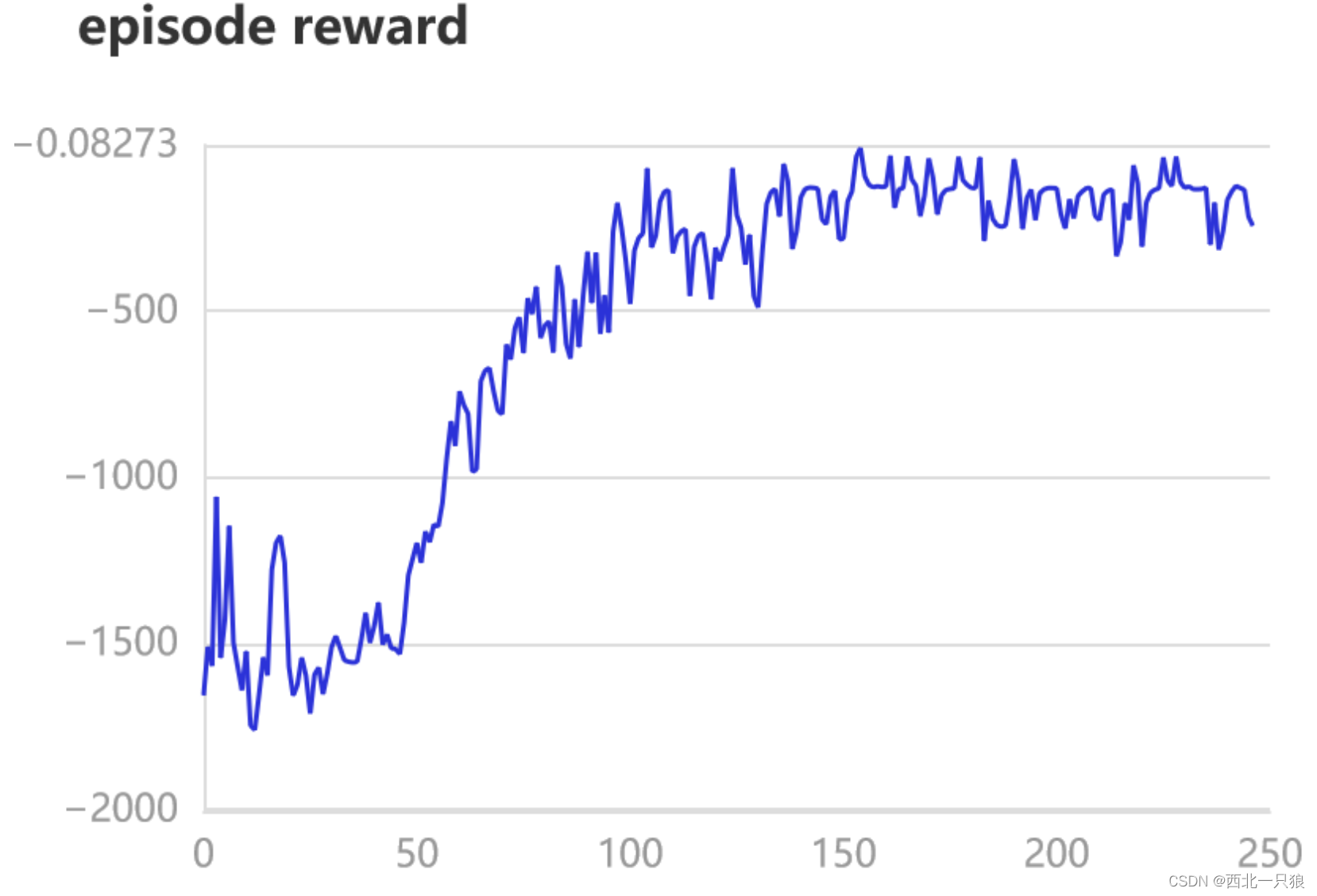
如果训练进行的正确,平均奖励将随着时间的推移而增加:
强化学习中奖励函数的作用就是引导智能体不断优化其策略以获得期待的未来累积的最大化奖励。大部分强化学习范例中的奖励函数通常是由系统设计人员手动编码。
对于某些强化学习问题,通常可以找到一些明显的奖励函数,如游戏中的得分、财务问题中的利润等。但是对于某些实际应用中的强化学习问题,其奖励函数不但是未知的,而且需要权衡很多不同方面的需求。如果奖励函数设置不合理,则智能体就有可能收敛到错误的方向或者学到的是次优的策略。
在自动驾驶应用中,奖励函数的设定不但要考虑到安全性和舒适性,还需要考虑如何让智能体更加符合人类驾驶员的驾驶习惯。然而,人类驾驶的控制行为比较复杂,在驾驶过程中需要权衡多方面的需求和约束,所以难以手动指定一个合理的奖励函数来引导智能体训练。而一个不合理的奖励函数会造成训练好的模型收敛到局部最小值甚至出现糟糕的表现。北京联合大学的智能驾驶团队对驾驶数据进行分析得到人类驾驶员的特征,并设计强化学习的奖励函数实现无人驾驶的纵向控制,使得智能体在纵向控制方面更加符合人类驾驶习惯。
TD3或者SAC。
跟驰模型
Pipes 模型和 Forbes 模型,它们都是从驾驶员的日常驾驶经验中总结出来的:
Pipes 模型:跟车的一个安全法则是在速度每增加 10 mph(十迈 或十英里每小时)时就使车间间距增加至少一个车长
Pipes 模型:为了安全,你和前车之间的车间时距必须大于或等于你的觉察-反应时间
挑战
车辆运动模型,过去传统的有跟驰模型、换道模型、交叉口通行模型,但是这些模型都是基于场景的,互相之间不具有通用性。随着场景爆炸,模型也处于不断地爆炸、膨胀的过程,在通用驾驶人模型的基础上,尝试建立从感知、决策到操控环节的通用模型,解决自动驾驶过程中模型爆炸的问题。
路段如何引导车辆,当我们知道什么时间从上一个交叉口出发、什么时间要到达下一个交叉口之后,怎么引导中间路段的车辆是最优的;如果我们知道交叉口的几何条件,以及网联自动驾驶车辆、人工驾驶车辆的交通需求,如何通过一套算法使通行能力得到显著的提升。