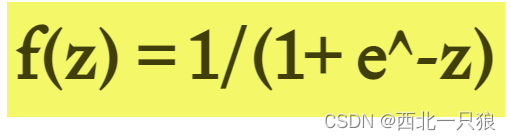背景
在所有有真实联络方式的线索中,合理的线索只占少数(感兴趣不等于一定会买),而真正能转化为交易的线索客户更是少之又少(就算我要买,也不一定非你不可),这时,如何从销售线索中取优就显得很有必要了。
销售线索的质量有高低之分是毋庸置疑的,但要比较准确的把好的销售线索筛选出来,随着大数据和人工智能的兴起,以数据为驱动的线索质量评级正变得越来越流行。不管是人工来给线索质量评级还是用机器来评级,高质量的销售线索总有一些常见特征,如下:
1、线索中的联系人对产品感兴趣或者有明确的购买意向
2、线索中的联系人对购买产品有决策权
3、线索包含的数据维度有助于帮助销售人员做后续的跟进和转化
4、线索转化成销售订单的成功率比较高
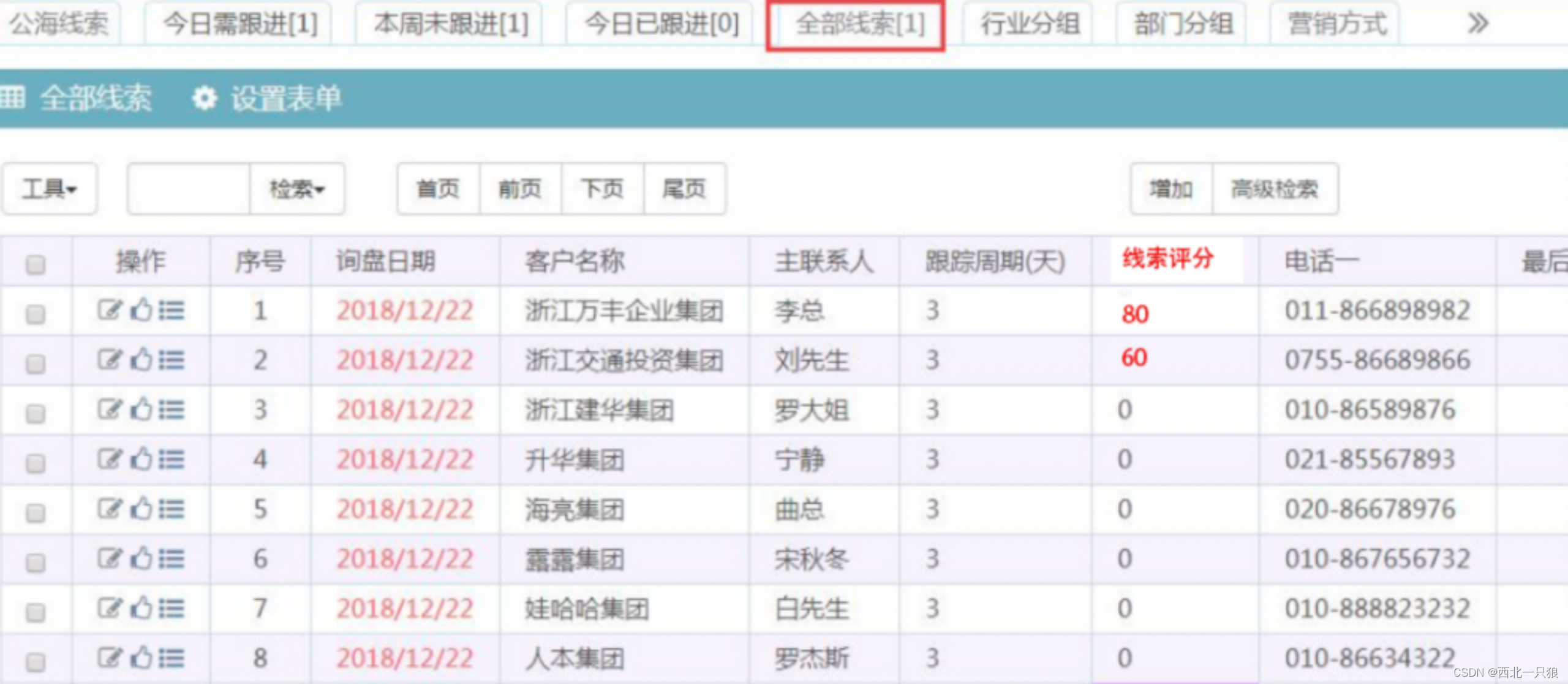
销售线索智能评分
销售线索智能评分主要依赖以下数据:
1、企业基本信息:企业的基本信息能初步判断客户的匹配度。主要包括企业规模、企业实力、企业成立时长、注册资金、公司性质、是否4A、信用等级、公司是否存在、企业邮箱是否正常、服务电话是否为空、人员规模等;
2、联系人画像:B2B通常是多人决策,小型公司的决策人数平均6-8人,大公司的购买决策高达20人以上。联系人在企业中的角色对销售线索转化十分重要 ,除了联系人的职务信息和关键操作行为(官网查看、自动化邮件点击、文档下载、营销内容查看、转发或退订等),还包括联系人在决策中的角色,联系人角色分为发起人、决策者、买方(管理采购过程人员)、影响者、使用者、门卫(负责公司信息流)等;
3、企业历史行为:基于历史成交画像动态评分持续判断客户的匹配度。主要包括企业近期的采购成交,如企业是否接触友商或者同类产品、最近是否购买了具有竞争力的解决方案、是否曾经购买我们的产品等