推荐系统算法大致发展流程如下,主要包括线性模型、树模型和神经网络模型。随着 DNN 在图像、语音、NLP 等领域取得突破,人们渐渐意识到 DNN 在特征表示上的天然优势。相继提出了使用 CNN 或 RNN 来做 CTR 预估的模型。但是,CNN 模型的缺点是:偏向于学习相邻特征的组合特征。 RNN 模型的缺点是:比较适用于有序列 (时序) 关系的数据。

特征组合
普通的线性模型,都是将各个特征独立考虑的,并没有考虑到特征与特征之间的相互关系。但实际上,大量的特征之间是有关联的。最简单的以电商为例,一般女性用户看化妆品服装之类的广告比较多,而男性更青睐各种球类装备。那很明显,女性这个特征与化妆品类服装类商品有很大的关联性,男性这个特征与球类装备的关联性更为密切。如果我们能将这些有关联的特征找出来,显然是很有意义的。
一般的线性模型为:

从上面的式子很容易看出,一般的线性模型压根没有考虑特征间的关联。为了表述特征间的相关性,我们采用多项式模型。在多项式模型中,特征
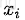
与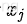
的组合用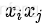
表示。为了简单起见,我们只考虑二阶交叉的情况,具体的模型如下:
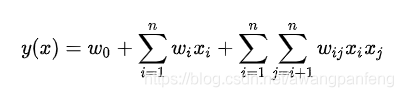
式中,n表示样本的特征数量,
表示第i个特征,与线性模型相比,FM的模型就多了后面特征组合的部分。
FM求解
从公式可以看出,组合特征的参数一共有 n(n−1)/2个,任意两个参数都是独立的。然而,在数据稀疏性普遍存在的实际应用场景中,二次项参数的训练是很困难的。其原因是,每个参数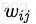
的训练需要大量
和
都非零的样本;由于样本数据本来就比较稀疏,满足
和
都非零”的样本将会非常少。训练样本的不足,很容易导致参数
不准确,最终将严重影响模型的性能。
如何解决二次项参数的训练问题呢?矩阵分解提供了一种解决思路。在model-based的协同过滤中,一个rating矩阵可以分解为user矩阵和item矩阵,每个user和item都可以采用一个隐向量表示。比如在下图中的例子中,我们把每个user表示成一个二维向量,同时把每个item表示成一个二维向量,两个向量的点积就是矩阵中user对item的打分。
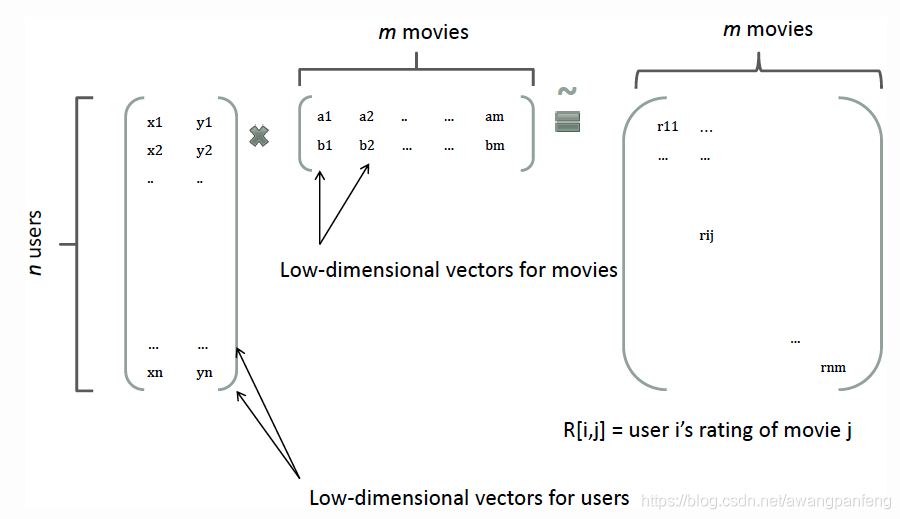

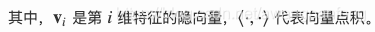
隐向量的长度为 k(k<<n),包含 k 个描述特征的因子,二次项的参数数量减少为 kn个,远少于多项式模型的参数数量。

公式2是一个通用的拟合方程,可以采用不同的损失函数用于解决回归、二元分类等问题,比如可以采用MSE(Mean Square Error)损失函数来求解回归问题,也可以采用Hinge/Cross-Entropy损失来求解分类问题。当然,在进行二元分类时,FM的输出需要经过sigmoid变换,这与Logistic回归是一样的。
直观上看,FM的复杂度是 O(kn^2^)。但是,通过公式(3)的等式,FM的二次项可以化简,其复杂度可以优化到 O(kn)。由此可见,FM可以在线性时间对新样本作出预测。
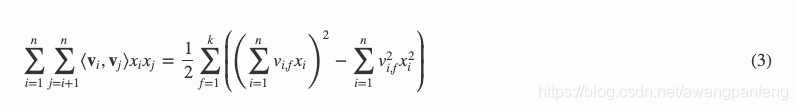
看一下FM的训练复杂度,利用SGD(Stochastic Gradient Descent)训练模型。模型各个参数的梯度如下:
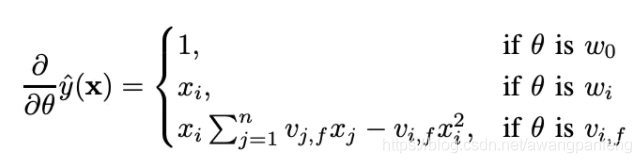
因此,FM参数训练的复杂度也是O(kn)。综上可知,FM可以在线性时间训练和预测,是一种非常高效的模型。
FM思想及实现
FM的全称是Factorization Machines,就是因子分解机的意思,为什么叫因子分解呢,就是因为他对传统的线性回归模型加了一个因子交叉项,你可以理解为把每一个特征和其他特征相乘后求和。
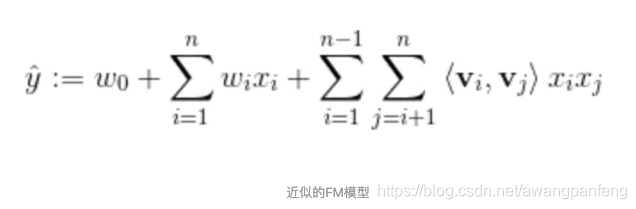
其实就是把W分解了,分解成两个矩阵相乘,这样的话其实就剩kn个参数需要我们计算了,降低了算法复杂度。可以发现参数矩阵w是一个*实对称矩阵,可以使用矩阵分解的方法分解,通过引入辅助向量又称为隐向量V来表示。


可以使用常见的梯度下降法对参数进行求解,为了对参数进行梯度下降更新,需要计算模型各参数的梯度表达式。
案例演示:用python实现FM算法,数据场景为二分类问题
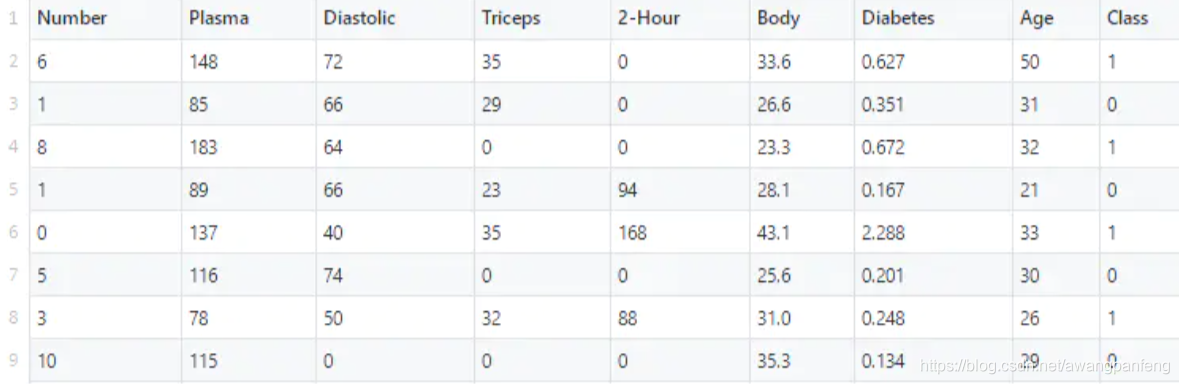
1 | ''' |
1 | import pandas as pd |