贷后风险预测,通常会通过人工方式,定期或不定期地通过与贷款人沟通,对贷款人的财务信息、经营状况的分析以及贷款资金的流向监测,来掌握可能造成违约风险和信用风险的因素,防止违约贷款。人工方式每月或每季度进行一次,遇到问题也只能依赖经验上报,等待风险管理部门决策后采取行动。面临以下几个主要问题:
1、人工投入大,预测时间长。层层上报并等待决策处理,占用风险控制中的宝贵时间;
2、人工预测质量良莠不齐。缺乏经验的工作人员无法将风险消弭在襁褓之中;
3、多种因素影响预测。市场环境多变、经济活动周期性以及企业信息不对称等因素干扰;
4、无法通过经验积累提升效率和准确率,不能形成良性闭环。
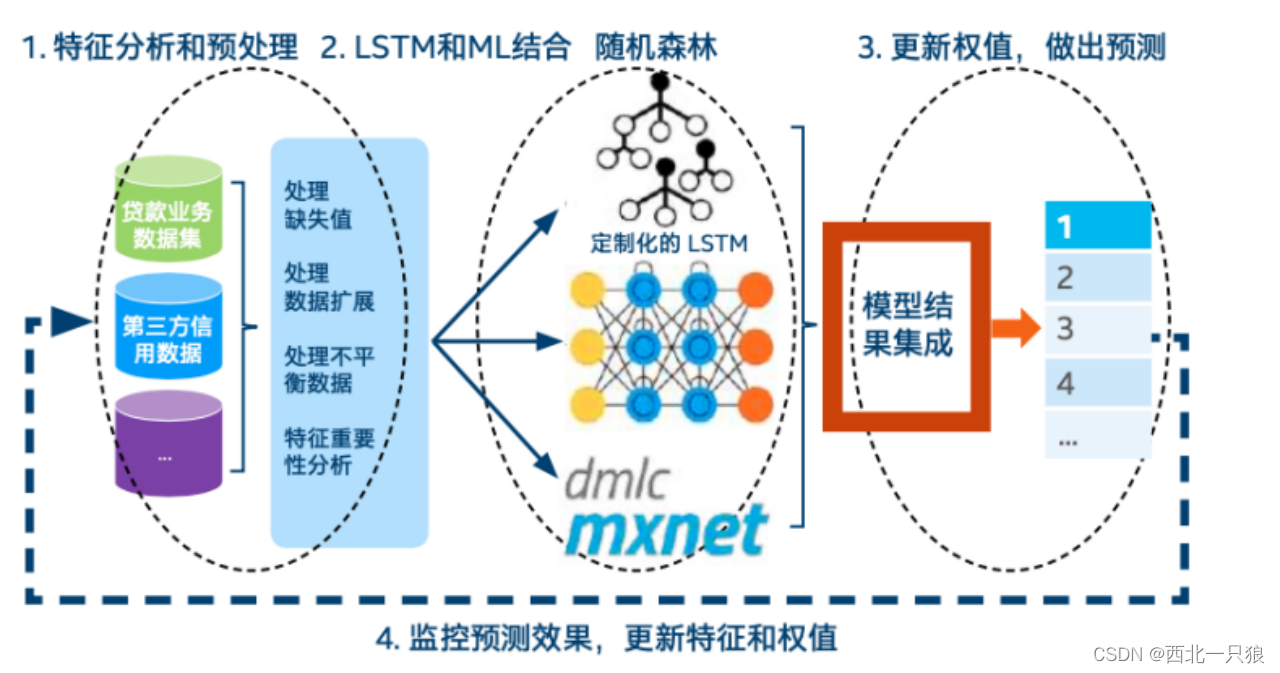
构建完整的信贷逾期风险预测AI架构,实现高准确率、低延时以及可解释的贷款逾期预测方案,就需要针对业务数据和环境数据进行分析和预测。
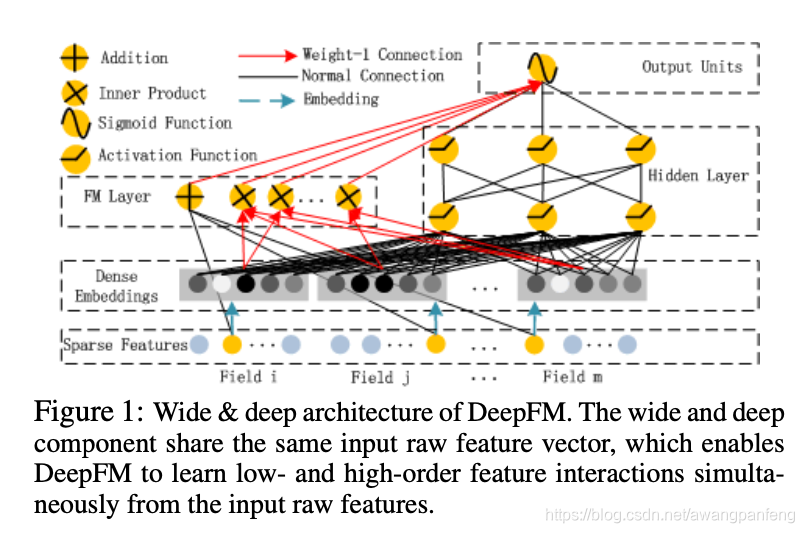
深度学习方法是信贷逾期风险预测中日益广泛应用的方案,但纯粹的深度学习方法存在着过程缺乏可解释性的缺陷,而金融机构往往需要对推理得到的结果进行解释。因此模型融合方法是解决该问题的一种非常有效的技术,通过将树模型 XGBoost 和 LSTM 深度学习模型进行融合,能使预测能力得到进一步增强,同时又使模型具备可解释性。如下为基于模型融合的信贷逾期风险预测结构图。
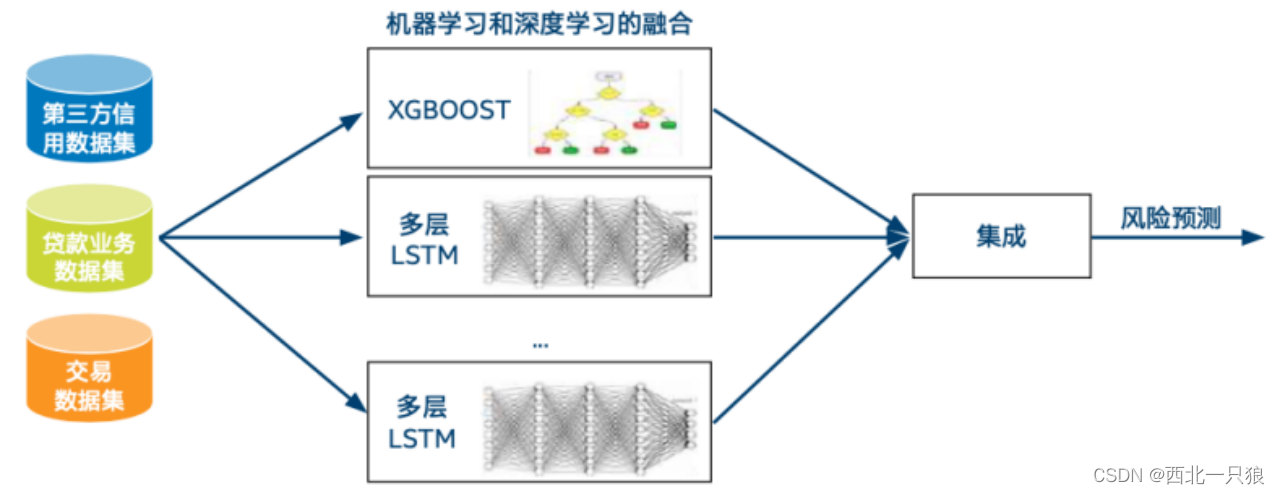
该模型的工作流程如下所示,主要包括四个工作流。