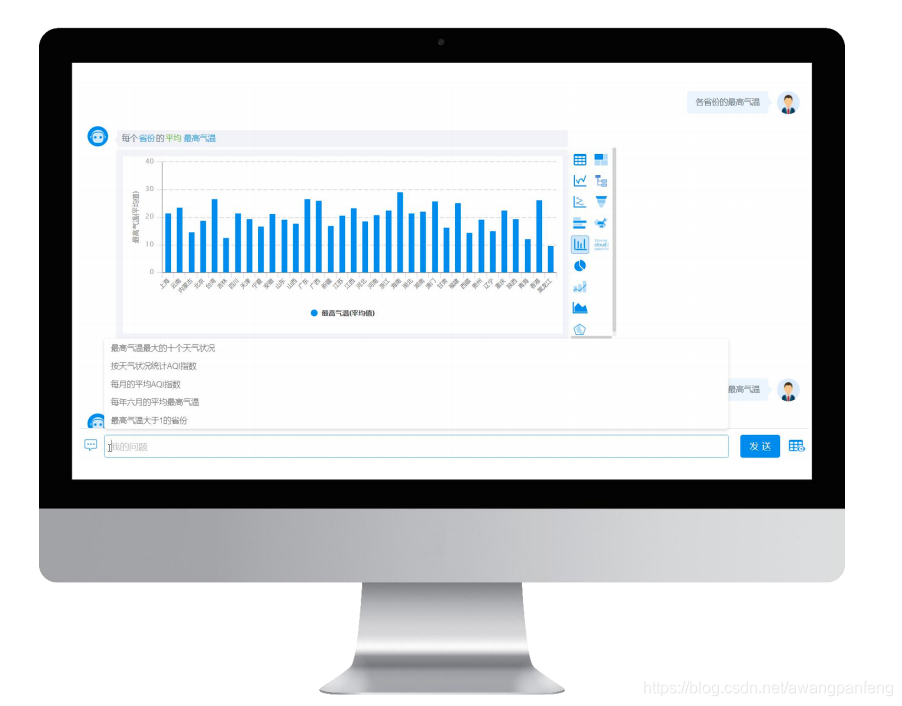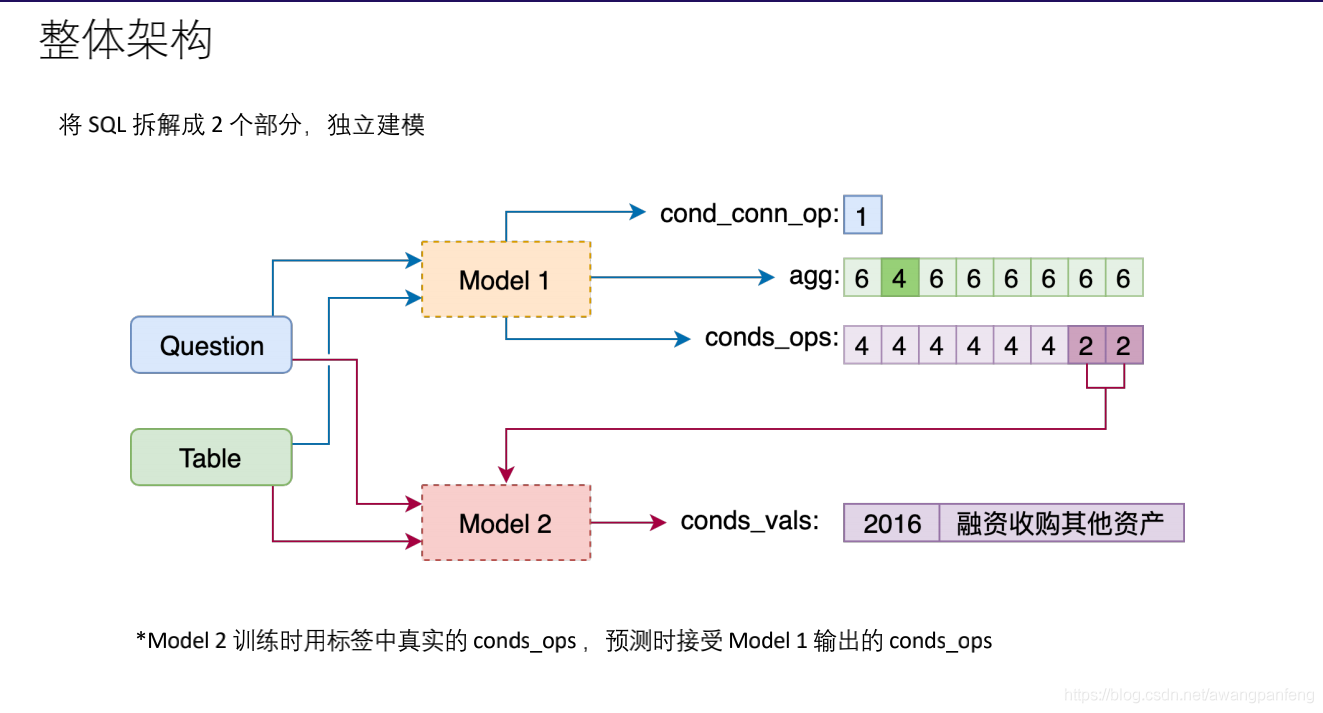
将任务拆解成两个部分,Model 1用于预测sel、agg、cond_conn_op和conds,Model 2用于预测conds_vals。先来看看准备的数据集是什么样的,数据集来自天池比赛,如果项目落地需要准备相应的数据:
1、table数据(数据库表数据)

2、”问题-结果“数据(人工格式化后的数据),参考上篇文档https://wiki.ingageapp.com/pages/viewpage.action?pageId=50664853。

Model 1的主要结构如下:
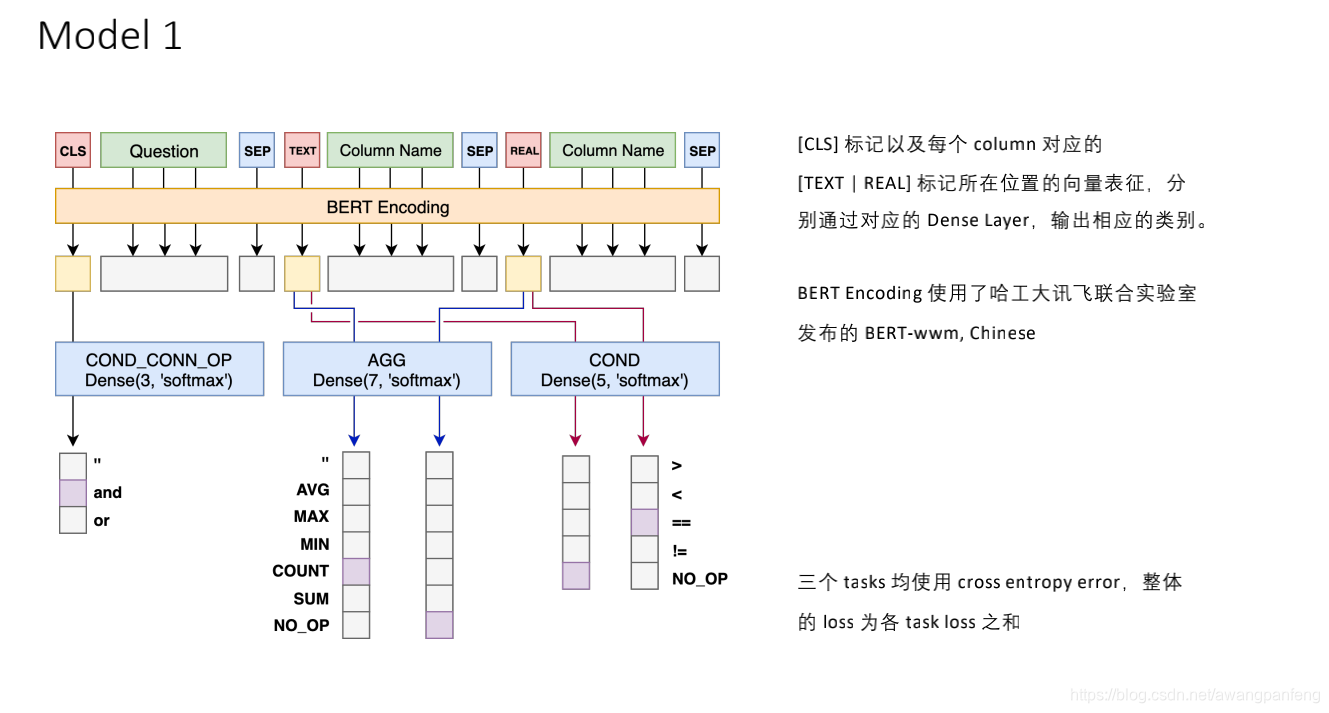
Python代码模型结构如下所示,主要利用了keras-bert库:

Model 2的结构如下:
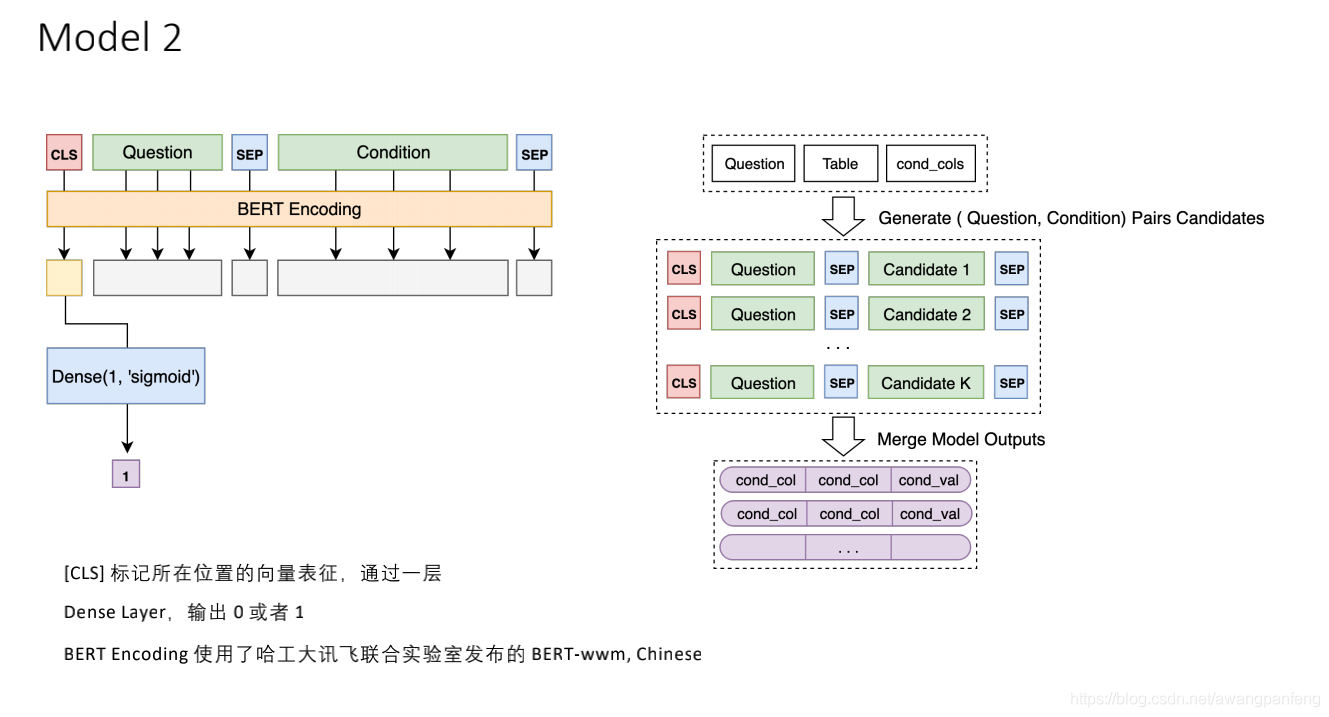
Model 2的代码实现如下所示,具体的中英文转义、数据优化、模型训练参数等细节代码详见附件。:
一般来讲,涉及NLP相关算法复杂度都较高,依赖于GPU,目前训练集“问题-结果”4万条,表格数据40MB,测试集和验证集“问题-结果”分别4千条,表格数据10MB左右,目前在Mac mini单机上训练Model 1耗时大概10天,Model 2小数据集运行成功,全数据训练报错,有待调试。