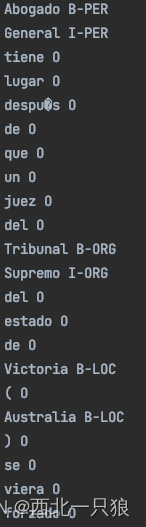
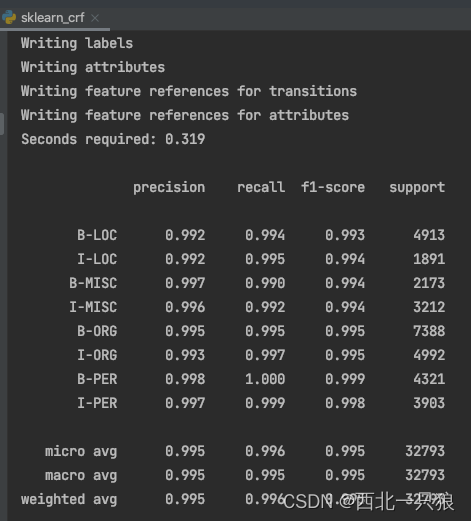
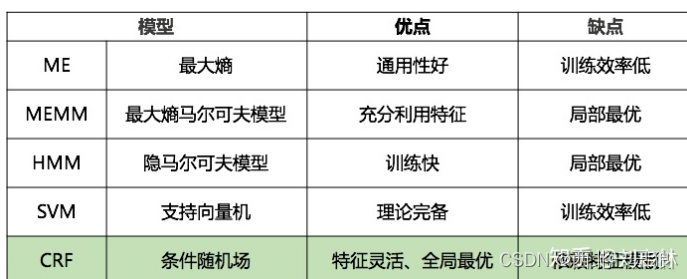
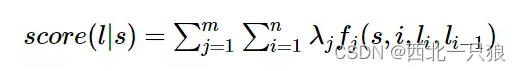import sklearn_crfsuite from sklearn_crfsuite import metrics
warnings.filterwarnings('ignore')
defload_data(data_path): data = list() data_sent_with_label = list() withopen(data_path, mode='r', encoding="latin-1") as f: for line in f: if line.strip() == "": data.append(data_sent_with_label.copy()) data_sent_with_label.clear() else: data_sent_with_label.append(tuple(line.strip().split(" "))) return data
# 一个单词多个特征函数 defword2features(sent, i): word = sent[i][0]
features = { 'bias': 1.0, 'word': word, 'word.isdigit()': word.isdigit(), } if i > 0: word1 = sent[i - 1][0] words = word1 + word features.update({ '-1:word': word1, '-1:words': words, '-1:word.isdigit()': word1.isdigit(), }) else: features['BOS'] = True
if i > 1: word2 = sent[i - 2][0] word1 = sent[i - 1][0] words = word1 + word2 + word features.update({ '-2:word': word2, '-2:words': words, '-3:word.isdigit()': word1.isdigit(), })
if i > 2: word3 = sent[i - 3][0] word2 = sent[i - 2][0] word1 = sent[i - 1][0] words = word1 + word2 + word3 + word features.update({ '-3:word': word3, '-3:words': words, '-3:word.isdigit()': word1.isdigit(), })
if i < len(sent) - 1: word1 = sent[i + 1][0] words = word1 + word features.update({ '+1:word': word1, '+1:words': words, '+1:word.isdigit()': word1.isdigit(), }) else: features['EOS'] = True
if i < len(sent) - 2: word2 = sent[i + 2][0] word1 = sent[i + 1][0] words = word + word1 + word2 features.update({ '+2:word': word2, '+2:words': words, '+2:word.isdigit()': word2.isdigit(), })
if i < len(sent) - 3: word3 = sent[i + 3][0] word2 = sent[i + 2][0] word1 = sent[i + 1][0] words = word + word1 + word2 + word3 features.update({ '+3:word': word3, '+3:words': words, '+3:word.isdigit()': word3.isdigit(), })
return features
# 一个句子多个单词 defsent2features(sent): return [word2features(sent, i) for i inrange(len(sent))]
defsent2labels(sent): return [ele[-1] for ele in sent]
if __name__ == '__main__':
train = load_data('./data/esp.train') valid = load_data('./data/esp.train') test = load_data('./data/esp.testa')
print(len(train), len(valid), len(test))
sample_text = ''.join([c[0] for c in train[0]]) sample_tags = [c[1] for c in train[0]] print(sample_text) print(sample_tags)
X_train = [sent2features(s) for s in train] y_train = [sent2labels(s) for s in train]
X_dev = [sent2features(s) for s in valid] y_dev = [sent2labels(s) for s in valid] # **表示该位置接受任意多个关键字(keyword)参数,在函数**位置上转化为词典 [key:value, key:value ] crf_model = sklearn_crfsuite.CRF(algorithm='lbfgs', c1=0.25, c2=0.018, max_iterations=100, all_possible_transitions=True, verbose=True) crf_model.fit(X_train, y_train)
defload_data(): train = _parse_data(open('data/train_data.data', 'rb')) test = _parse_data(open('data/test_data.data', 'rb'))
word_counts = Counter(row[0].lower() for sample in train for row in sample) vocab = [w for w, f initer(word_counts.items()) if f >= 2] chunk_tags = ['O', 'B-PER', 'I-PER', 'B-LOC', 'I-LOC', "B-ORG", "I-ORG"]
# save initial config data withopen('model/config.pkl', 'wb') as outp: pickle.dump((vocab, chunk_tags), outp)
def_parse_data(fh): # in windows the new line is '\r\n\r\n' the space is '\r\n' . so if you use windows system, # you have to use recorsponding instructions
string = fh.read().decode('utf-8') data = [[row.split() for row in sample.split(split_text)] for sample in string.strip().split(split_text + split_text)] fh.close() return data
def_process_data(data, vocab, chunk_tags, maxlen=None, onehot=False): if maxlen isNone: maxlen = max(len(s) for s in data) word2idx = dict((w, i) for i, w inenumerate(vocab)) x = [[word2idx.get(w[0].lower(), 1) for w in s] for s in data] # set to <unk> (index 1) if not in vocab
y_chunk = [[chunk_tags.index(w[1]) for w in s] for s in data]
defprocess_data(data, vocab, maxlen=100): word2idx = dict((w, i) for i, w inenumerate(vocab)) x = [word2idx.get(w[0].lower(), 1) for w in data] length = len(x) x = pad_sequences([x], maxlen) # left padding return x, length
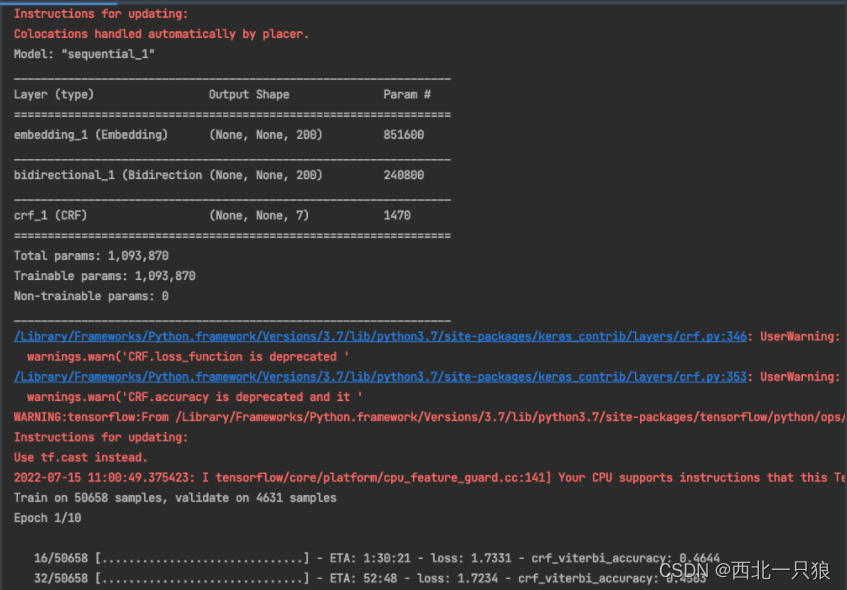
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2022/07/14 6:32 下午 # @Author : wangpf@neocrm.com # @File : bilstm_crf_model.py import pickle import platform from collections import Counter import numpy as np import numpy from keras.layers import Embedding, Bidirectional, LSTM from keras.models import Sequential from keras.preprocessing.sequence import pad_sequences from keras_contrib.layers import CRF
defload_data(): train = _parse_data(open('data/train_data.data', 'rb')) test = _parse_data(open('data/test_data.data', 'rb'))
word_counts = Counter(row[0].lower() for sample in train for row in sample) vocab = [w for w, f initer(word_counts.items()) if f >= 2] chunk_tags = ['O', 'B-PER', 'I-PER', 'B-LOC', 'I-LOC', "B-ORG", "I-ORG"]
# save initial config data withopen('model/config.pkl', 'wb') as outp: pickle.dump((vocab, chunk_tags), outp)
def_parse_data(fh): # in windows the new line is '\r\n\r\n' the space is '\r\n' . so if you use windows system, # you have to use recorsponding instructions
string = fh.read().decode('utf-8') data = [[row.split() for row in sample.split(split_text)] for sample in string.strip().split(split_text + split_text)] fh.close() return data
def_process_data(data, vocab, chunk_tags, maxlen=None, onehot=False): if maxlen isNone: maxlen = max(len(s) for s in data) word2idx = dict((w, i) for i, w inenumerate(vocab)) x = [[word2idx.get(w[0].lower(), 1) for w in s] for s in data] # set to <unk> (index 1) if not in vocab
y_chunk = [[chunk_tags.index(w[1]) for w in s] for s in data]
defprocess_data(data, vocab, maxlen=100): word2idx = dict((w, i) for i, w inenumerate(vocab)) x = [word2idx.get(w[0].lower(), 1) for w in data] length = len(x) x = pad_sequences([x], maxlen) # left padding return x, length
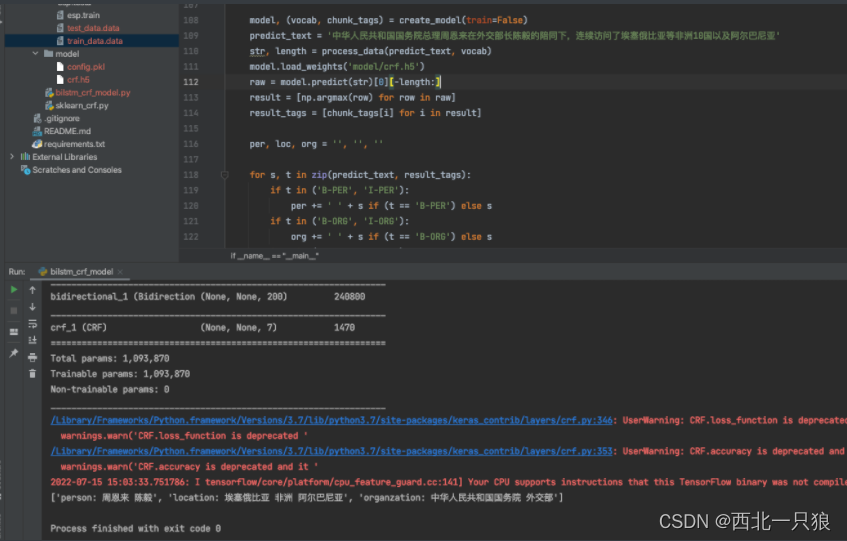
model, (vocab, chunk_tags) = create_model(train=False) predict_text = '中华人民共和国国务院总理周恩来在外交部长陈毅的陪同下,连续访问了埃塞俄比亚等非洲10国以及阿尔巴尼亚' str, length = process_data.process_data(predict_text, vocab) model.load_weights('model/crf.h5') raw = model.predict(str)[0][-length:] result = [np.argmax(row) for row in raw] result_tags = [chunk_tags[i] for i in result]
per, loc, org = '', '', ''
for s, t inzip(predict_text, result_tags): if t in ('B-PER', 'I-PER'): per += ' ' + s if (t == 'B-PER') else s if t in ('B-ORG', 'I-ORG'): org += ' ' + s if (t == 'B-ORG') else s if t in ('B-LOC', 'I-LOC'): loc += ' ' + s if (t == 'B-LOC') else s
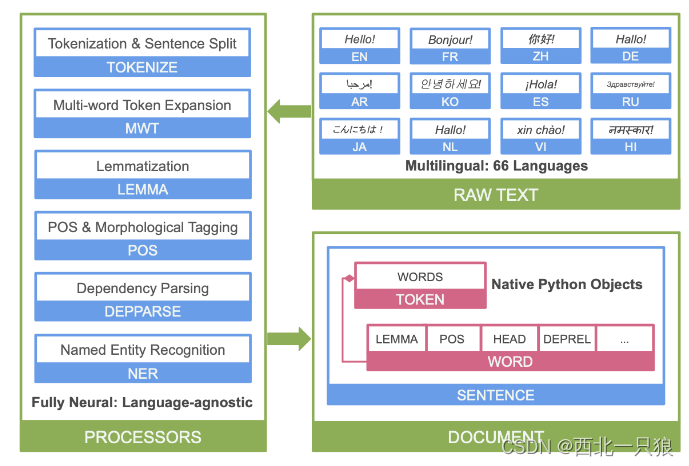
if __name__ == '__main__': # 可以通过pipeline预加载不同语言的模型,也可以通过pipeline选择不同的处理模块,还可以选择是否使用GPU: zh_nlp = stanza.Pipeline('zh', use_gpu=False) text = "马云在1996年11月29日来到杭州的阿里巴巴公司。"
doc = zh_nlp(text) for sent in doc.sentences: print("Sentence:" + sent.text) # 断句 print("Tokenize:" + ' '.join(token.text for token in sent.tokens)) # 中文分词 print("UPOS: " + ' '.join(f'{word.text}/{word.upos}'for word in sent.words)) # 词性标注(UPOS) print("XPOS: " + ' '.join(f'{word.text}/{word.xpos}'for word in sent.words)) # 词性标注(XPOS) print("NER: " + ' '.join(f'{ent.text}/{ent.type}'for ent in sent.ents)) # 命名实体识别