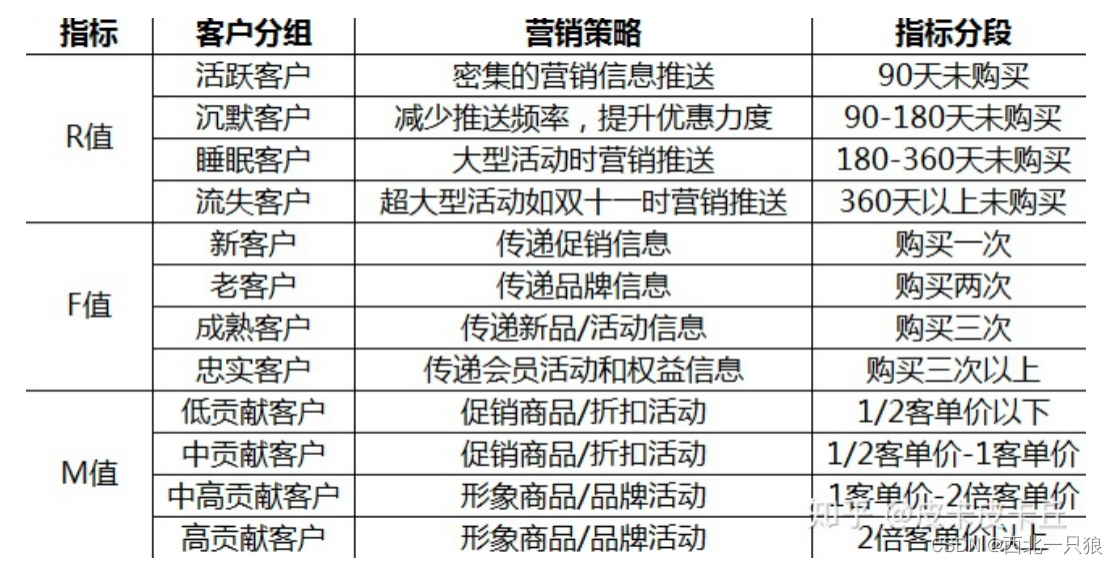
目前AI实验室产品推荐系统仅面向好孩子电商场景,只是AI场景中的一小部分。要打造行业解决方案,可以参考4paradigm产品行业解决方案:
1、智慧银行:助力银行实现数智化银行战略转型发展,拓展全业务领域、全渠道、全流程的AI规模化应用。
(1)精准营销。通过人工智能模型应用,在线上、线下各业务渠道对客户开展有针对性的精准化营销,提升营销成功率,减少对客户的打扰。
(2)实时反欺诈。依托于业内领先的机器学习、自然语言处理、图关系、知识图谱等技术构建AI智能反欺诈大脑,全面覆盖欺诈和信用风险业务场景。
(3)智能反洗钱。通过AI反洗钱技术大幅降低反洗钱合规领域的人力成本,识别可疑案件,辅助分析和报送,解决反洗钱机构“漏报”和“多报”问题。
(4)运营优化。结合机器学习、知识图谱、自然语言处理等技术,实现对公业务运营优化管理,服务营销商机挖掘、企业授信、风险传导预警等业务场景。
2、智能保险:实现从营销、投保、理赔到保全的全流程管理。
(1)保险客户在线化智能运营。帮助保险公司与经纪代理公司完成线上化营销转型。同时辅助代理人获取更个性化的产品推荐信息。
(2)智能核保/核赔。依托机器学习平台的强大算力,提供核保/核赔阶段风险分类模型,对高风险进件快速审核和分类。
(3)智能化健康管理方案。提供从医疗单证识别、慢性病知识库到健康管理产品的全流程健康管理方案。
(4)车险智能定损。利用 CV技术,完成车辆损坏部位自动识别与定位。并依靠机器学习模型完成定损与理赔风控管理。
3、智慧零售:帮助企业提升“人货场”全面智慧化管理水平,达到新零售降本增效的目的。
(1)精准营销。通过智慧零售AI技术的运用,精准的建立360度客户画像,对消费者的需求进行预测,并提供“千人千面”的个性化商品推荐,促进销售转化、提升新零售销售业绩。
(2)智能运营。从门店选址、智能选品、智能定价等各个运营环节的智慧化入手,助力企业提高运营效率,降低对高成本人才的依赖性,实现既标准又智能的智慧零售运营管理。
(3)智慧供应链。以消费者需求洞察为导向,结合AI技术预测销量,新零售实现灵活生产、分发、补货配货、降低库存损耗,降低企业成本。
(4)智能客服。高效、高质量地满足消费者商品咨询、自助购物等需求,大幅提高消费者满意度、提升店铺询单转化率、节省客服人力成本。
4、智慧医疗:实现医疗医药企业全链路的智能化转型。
(1)慢病风险预测。基于领先的AI技术和全球最大最新的代谢性疾病样本库,建立中国慢性病高精准筛查系列产品,可同时对心脑血管、心血管、脑卒中、糖尿病和高血压5种常见高发慢性疾病进行风险评估。
(2)疫情推演系统。利用强化学习、环境学习等决策类AI技术构建数据驱动的省市区县级新型冠状病毒传播数字孪生系统,推演不同管控方案对疫情趋势的影响,为制定科学有效的复工复产方案提供有效参考。
(3)新生儿体重预测。利用自动机器学习技术训练出大规模机器学习预测模型,用以辅助无ML基础的医师进行新生儿体重预测,对指导生产方式等方面提供重要参考。
(4)胰腺癌术后生存分析。利用自动GBDT算法调参等技术训练出大规模机器学习预测模型,预测精度提高12%,为手术决策提供有利参考。
5、智慧制造:智慧制造从实时生产的每个零件中学习,从产线运转的每台机器中洞察,人工智能帮助未来工厂从数字化到智能化。