简介
MADlib 是一个基于 SQL 的数据库内置的开源机器学习库,具有良好的并行度和可扩展性,有高度的预测精准度。MADlib 1.14 可以与 PostgreSQL、Greenplum 和 HAWQ 等数据库系统无缝集成。
通常 SQL 查询能发现数据最明显的模式和趋势,但要想获取数据中最为有用的信息,需要的其实是完全不同的一套技术,一套牢固扎根于数学和应用数学的技能(机器学习)。将 SQL 的简单易用与数据挖掘的复杂算法结合起来,充分利用两者的优势和特点,对于广大传统数据库应用技术人员来说,就可将他们 长期积累的数据库操作技能复用到机器学习领域。
MADlib 提供了可在 SQL 查询语句中调用的函数,即可以用 select + function name 的方式来调用这个库。这就意味着,所有的数据调用和计算都在数据库内完成而不需要数据的导入导出。
MADlib 是 SQL 中的机器学习库,就注定它不关心数据可视化,本身不带数据的图形化表示功能。MADlib 作为工具,并不是传统意义上的机器学习系统软件,而只是一套可在 SQL 中调用的函数库,其出发点是让数据库技术人员用 SQL 快速完成简单的机器学习工作,比较适合做一些简单的、特征相对明显的机器学习。
设计思想
MADlib 架构的关键设计思想体现在以下方面:
操作数据库内的本地数据,避免在多个运行时环境之间不必要地移动数据。
充分利用数据库引擎功能,但将机器学习逻辑从数据库特定的实现细节中分离出来。
利用 MPP 无共享技术提供的并行性和可扩展性,如 Greenplum 或 HAWQ 数据库系统。
开放实施,保持与 Apache 社区的积极联系和持续的学术研究。
MADlib 库表现为数据库内置的函数。当函数在 SQL 语句中执行时,可以充分利用数据库引擎提供的功能。在客户端,可以使用Jupyter、 Zeppelin、psql 等工具连接数据库并调用 MADlib Function。MADlib 预处理后根据具体算法生成多个查询传入数据库服务器,之后数据库服务器执行查询并返回 String(一般是一个或多个存放结果的表), MADlib 函数调用过程的执行流程如下:
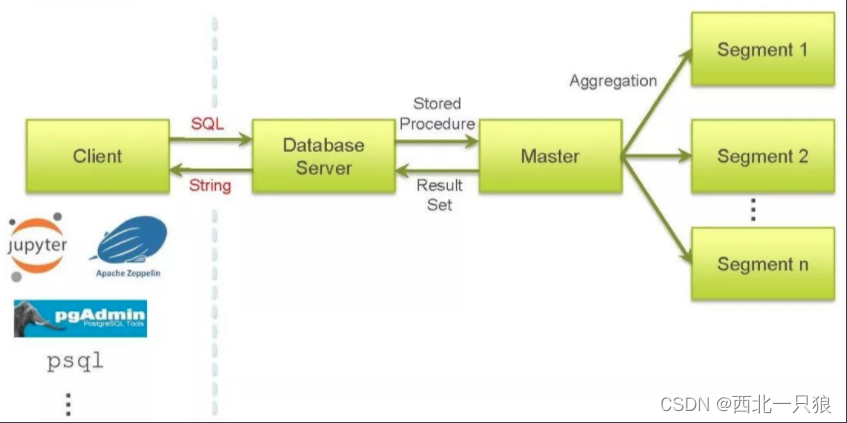
MADlib架构如下所示,包含四个主要组件:
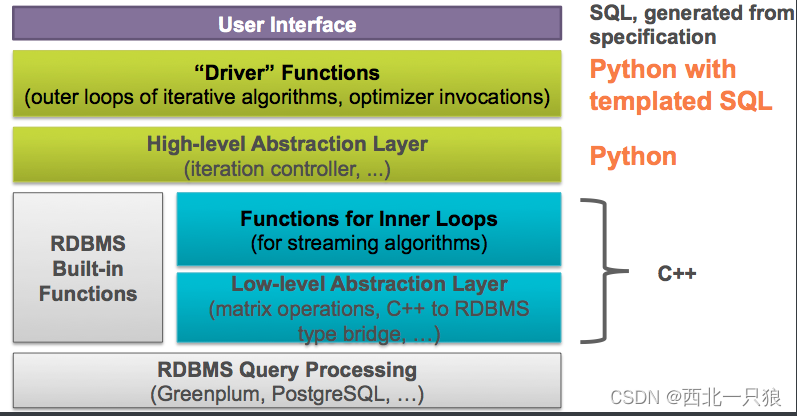
1、Python调用SQL模版实现的驱动函数:
2、Python实现的高级抽象层:负责算法流程控制
3、C++实现的核心函数:实现特定机器学习算法,注重性能
4、C++实现的低级数据库抽象层:对所有的 PostgreSQL 数据库内核实现细节进行抽象
支持的模型类型
MADlib支持以下机器学习模型类型:
回归:预测输出值
分类:分类目标
关联规则:购物篮分析
聚类:非监督分类
主题建模:文本领域发掘相似数据组
描述性统计:数据集分布情况
模型验证:测试数据评估模型
安装与卸载
在不同的数据库系统,安装过程不尽相同。以在 Greenplum 中安装 MADlib 为例:
1、下载MADlib 二进制压缩包
2、上传压缩包至Greenplum的Master主机
3、解压安装gppkg文件
4、将 MADlib 函数添加到 Greenplum 数据库
将madlib添加至testdb命令如下:
1 | $GPHOME/madlib/bin/madpack install -s madlib -p greenplum -c gpadmin@mdw:5432/testdb |
卸载:
1 | gppkg -r madlib-1.18.0+2-gp6-rhel7-x86_64 |
数据类型
和其他机器学习语言或工具一样,MADlib 操作的基本对象也是向量与矩阵。在 MADlib中,对向量和矩阵的操作是通过一系列函数完成的
向量操作函数:
1 | -- 向量加法 |
矩阵运算函数:
1 | -- 稠密矩阵表生成稀疏表示的表 |
使用
逻辑回归算法使用如下:
1 | -- 创建表格 |
自定义深度学习模型实现如下,可采用Jupyter,以Keras为例,数据处理是一样的:
1 | -- 导入数据 |
模型定义与实现:
1 | from tensorflow import keras |
总结
MADlib的优点和缺点一样明显,优势是存储和计算是一体,通过简单的SQL语句就可以实现机器学习模型训练,而且还兼容自定义的深度模型,DBA也可以通过简单的语句实现机器学习算法,简单优雅
缺点也一样突出,存储和计算一体,复杂的深度模型必然会占用计算资源,这可能直接影响线上其他服务。如果涉及NLP任务,需要GPU资源支持,显然也不是MADlib能做到的了,这种情况还是需要动态申请计算资源,运算完及时释放,同时保存中间数据