Generative Adversarial Imitation Learning – 这篇是首创GAIL的论文,数学比较多 大概看一下就行 不用读太深
GAIL-Imitating Driver Behavior with Generative Adversarial Networks 这篇是GAIl模型用在NPC车辆上的第一篇论文
Wasserstein-GAN 是GAIL的训练框架 GAN的变体
Info Gail是引入了隐变量,使一个模型可以训练出多种驾驶风格
RAIL是对强化学习的Reward Function进行了改动 对危险驾驶行为进行了惩罚
模仿学习
模仿学习方法 通过模仿专家演示的样本以解决决策问题,它不需要从环境中获得奖赏反馈, 其反馈信息来自于专家的决策样本。在很多实际问题中,相较于设置合适的奖赏函数,获取专家样本往往更容易且代价更小。
模仿学习方法可以分为两类:行为克隆方法(Behavioral Cloning,简称 BC)和基于逆向强化学习的模仿学习方法(Imitation Learning via Inverse Reinforcement Learning,简称IRL-IL)
- 行为克隆方法的主要思想是直接克隆专家样本在各状态处的单步动作映射,即对专家样本进行监督学习.BC并不考虑当前状态之后的长远影响.在有足够多专家样本的前提下,它具有良好的表现.由于不考虑长远影响,BC会将细微的误差在序贯的决策过程中逐步放大,即产生级联误差问题。
- 逆向强化学习假设专家策略等价于由未知的真实奖赏函数推导出的最优策略。逆向强化学习是RL的逆向过程,它根据给定的专家样本求解未知的奖赏函数.基于解的奖赏函数,通过RL方法求解最优策略的方式,间接地还原专家策略.这种模仿专家的方式使IRL-IL具备了长远规划的能力
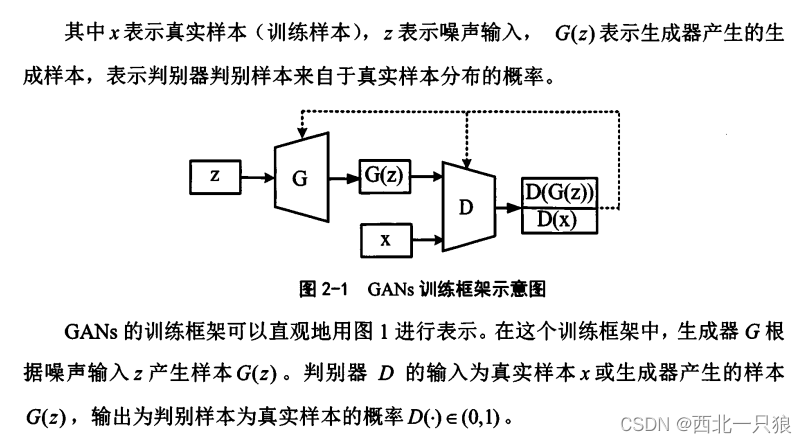
基于生成对抗网络的模仿学习方法(GANs-IL)从IRL-IL发展而来,是一 类结合了生成对抗网络的模仿学习方法.两者的主要区别是奖赏函数、策略的表示模型以及模型的训练方式.GANs-IL用两个神经网络来表示IRL-IL中的奖赏函数和策略,并用对抗的方式来优化这两个网络的参数.原始的生成对抗网络由生成模型(又称生成器)和判别模型(又称判别器)这两个相对抗的网络模型共同构成.
模仿学习的目标是学习得到与专家尽可能相似的决策模型.因此,模仿学习的评价标准一般为学习得到的策略与专家策略的性能对比。