Generative Adversarial Imitation Learning – 这篇是首创GAIL的论文,数学比较多 大概看一下就行 不用读太深
GAIL-Imitating Driver Behavior with Generative Adversarial Networks 这篇是GAIl模型用在NPC车辆上的第一篇论文
Wasserstein-GAN 是GAIL的训练框架 GAN的变体
Info Gail是引入了隐变量,使一个模型可以训练出多种驾驶风格
RAIL是对强化学习的Reward Function进行了改动 对危险驾驶行为进行了惩罚
模仿学习
模仿学习方法 通过模仿专家演示的样本以解决决策问题,它不需要从环境中获得奖赏反馈, 其反馈信息来自于专家的决策样本。在很多实际问题中,相较于设置合适的奖赏函数,获取专家样本往往更容易且代价更小。
模仿学习方法可以分为两类:行为克隆方法(Behavioral Cloning,简称 BC)和基于逆向强化学习的模仿学习方法(Imitation Learning via Inverse Reinforcement Learning,简称IRL-IL)
- 行为克隆方法的主要思想是直接克隆专家样本在各状态处的单步动作映射,即对专家样本进行监督学习.BC并不考虑当前状态之后的长远影响.在有足够多专家样本的前提下,它具有良好的表现.由于不考虑长远影响,BC会将细微的误差在序贯的决策过程中逐步放大,即产生级联误差问题。
- 逆向强化学习假设专家策略等价于由未知的真实奖赏函数推导出的最优策略。逆向强化学习是RL的逆向过程,它根据给定的专家样本求解未知的奖赏函数.基于解的奖赏函数,通过RL方法求解最优策略的方式,间接地还原专家策略.这种模仿专家的方式使IRL-IL具备了长远规划的能力
基于生成对抗网络的模仿学习方法(GANs-IL)从IRL-IL发展而来,是一 类结合了生成对抗网络的模仿学习方法.两者的主要区别是奖赏函数、策略的表示模型以及模型的训练方式.GANs-IL用两个神经网络来表示IRL-IL中的奖赏函数和策略,并用对抗的方式来优化这两个网络的参数.原始的生成对抗网络由生成模型(又称生成器)和判别模型(又称判别器)这两个相对抗的网络模型共同构成.
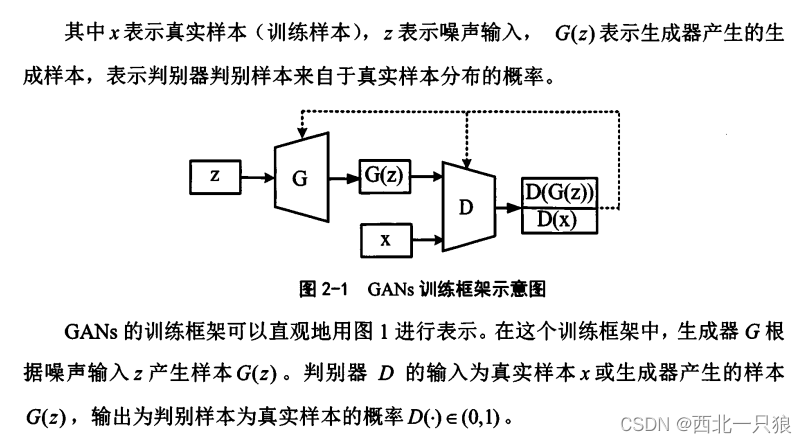
模仿学习的目标是学习得到与专家尽可能相似的决策模型.因此,模仿学习的评价标准一般为学习得到的策略与专家策略的性能对比。
在模仿学习中,获取专家样本集合的方式主要有以下两种:1)由人类专家示范而获得专家样本集合;2)通过强化学习方法对专家手工定义的标准奖赏函数学习得到贪婪策略,再由贪婪策略得到专家样本集合。然而,RL方法获得的贪婪策略可能不等价于最优策略。因而,这些由不同RL方法得到的贪婪策略的性能也各不相同。因此,通过RL方法得到的专家样本集合并没有形成标准。
目前,模仿学习问题多以仿真实验环境为主,如仿真小车、虚拟机器人控制等。对于不同的模仿学习任务,专家样本集合的获取方式并不固定。对于一些难度较大的模仿学习任务,标准的奖赏函数往往难以定义。因此,通过专家亲身示范行为动作获取专家样本集合的方式更为直接。对于一些存在危险的模仿学习任务,在虚拟环境中通过RL方法获得专家样本集合的方式更为恰当。
GAIL
Generative Adversarial Imitation Learning 最早出现且最具代表性的 GANs-IL方法,2016年提出.在 GAIL中,根据输入状态输出动作的策略可类比为生成器,而根据输入专家样本或生成样本输出奖赏值的奖赏函数可类比为判别器.从而,GAIL将求解奖赏函数的过程类比作判别器的训练过程,将策略的学习过程类比作生成器的训练过程.
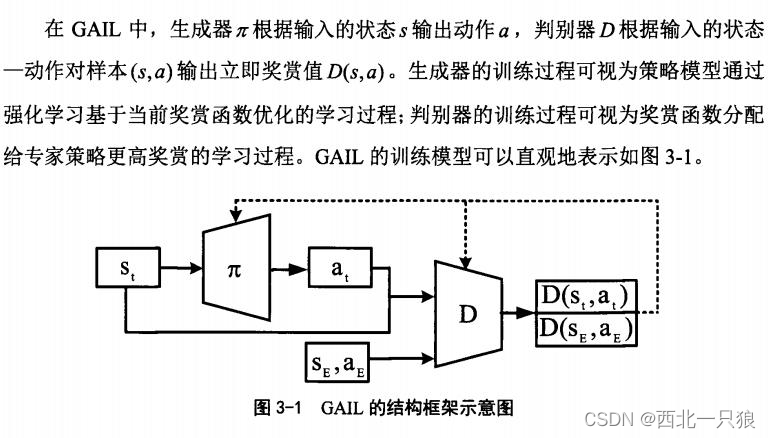
存在的问题:
- 模态崩塌问题:指生成模型产生的生成样本塌缩于真实样本分布的某一模态下的子分布,而无法覆盖全部真实样本分布。以图片样本为例,模态崩塌将导致生成模型产生的图片样本只能表现出单幅画面或单一风格,而丧失了样本的多样性
- 生成样本利用效率低:是GAIL假设策略为随机性策略并以无模型RL方法来学习策略。由于随机性策略采样动作的过程是不可微分的,因此反向传播的链式求导在策略模型万的动作节点处中断。在随机环境中,智能体的状态迁移过程是随机的。
ACGAIL
当专家样本服从多个模态下的子分布时,模仿学习的单一模态假设将导致模态崩塌。因此,假设专家具有多个模态的模仿学习方法更为合理。多模态的模仿学习放宽了单一模态的假设,它假设专家样本具有多个模态:专家演示的样本不限于单一模态而是来自不同模态下的多个子分布。基于多模态模仿学习的假设,GAIL的模态崩塌问题可以得到缓解。
在GAIL的基础上加入了辅助的网络模型,提出了带辅助分类器的生成对抗模仿学习(Generative Adversarial Imitation Leaming with Auxiliary Classifier,ACGAIL),新的辅助网络用来对样本所属的模态类别进行分类,从而帮助原始GAIL的模型重构关于模态的条件信息.
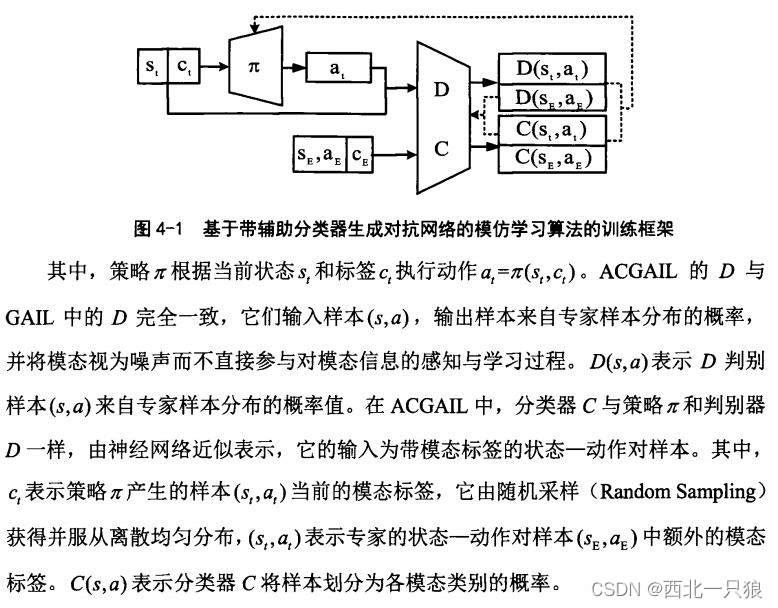
InfoGAIL
基于互信息最大化的生成对抗模仿学习(Information Maximizing Generative Adversarial Imitation Learning,InfoGAIL)。InfoGAIL将信息论中的互信息概念运用到了GAIL中。通过最大化互信息的原理,InfoGAIL能增强策略产生的样本与模态隐变量之间的相关性,从而实现无监督的多模态学习。
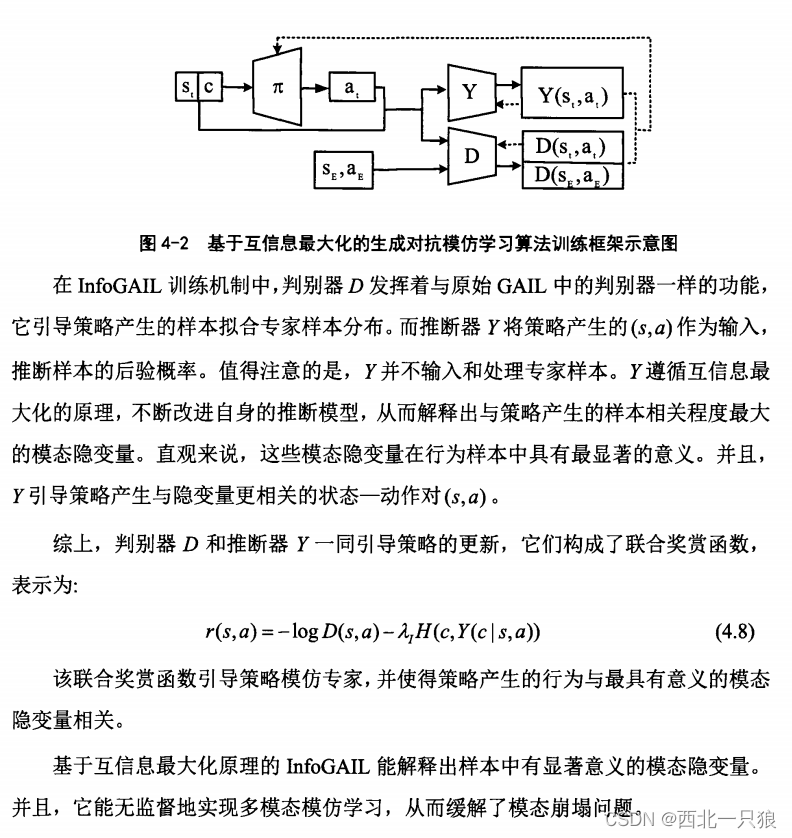
ACGAIL与InfoGAIL两种方法的模态变量的先验分布假设是一致的。这两种方法均通过随机采样获得模态变量,且假设专家样本存在有限种模态,模态变量服从离散均匀分布。它们都在原始GAIL算法结构中引入了额外的分类模型,分别为分类器C和推断器Y。ACGAIL的分类器C能利用已有的模态标签进行有监督训练,而InfoGAIL的推断器能无监督地训练。不仅如此,分类器C和推断器Y均与判别器联合构成了奖赏函数。
MAGAIL
多智能体生成对抗模仿学习(Multi-Agent Genrative Adversarial Imitation Learning,MAGAIL)假设环境中存在k个智能体,并有相应的k个判别器.其中,每个判别器均对相应智能体的策略与该智能体的专家策略进行评分,并尽可能地给予专家策略较高的分值,同时给予智能体的策略较低的分值.每个智能体则尽可能产生能够欺骗判别器的行为,从而在判别器的引导下实现对专家策略的模仿学习.
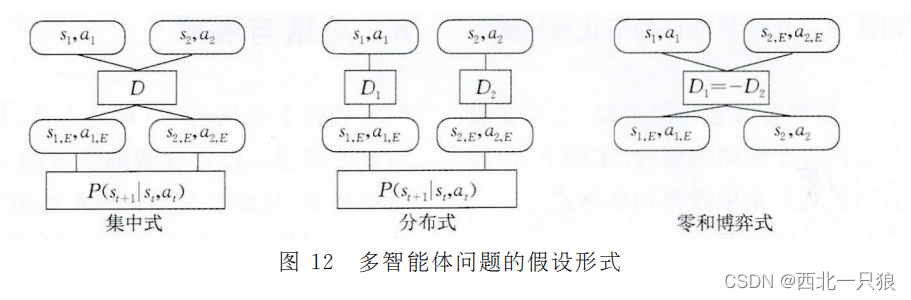
在多智能体的学习问题中,智能体相互之间的关系存在着一定的先验假设.比如,各个智能体之间存在着合作、竞争或相混合的假设.在不同的假设前提下,多智能体问题中的判别器存在不同的假设形式。
- 集中式.当多智能体之间符合完全合作的关系时,MAGAIL中的智能体实际上共享着同一个判别器.此时,这种特殊情况可以被理解为原始的GAIL,而其学习得到的联合策略能够应用于所有智能体
- 分布式.当智能体之间没有存在奖赏的相关性假设时,每个智能体对应的判别器将采取各不相同的评分标准.然而,这些判别器由于不断地与环境进行间接的交互,它们相互之间也并非是完全独立的
- 零和博弈式.假设两个智能体之间处于完全竞争的关系,那么它们收到的奖赏互为相反数.在零和博弈中,智能体不需环境进行额外的交互,判别器直接对智能体与专家的联合样本进行判别训练。
WARNING: The repository located at mirrors.aliyun.com is not a trusted or secure host and is being ignored. If this repository is available via HTTPS we recommend you use HTTPS instead, otherwise you may silence this warning and allow it anyway with ‘–trusted-host mirrors.aliyun.com’.
ERROR: Could not find a version that satisfies the requirement carla (from versions: none)
ERROR: No matching distribution found for carla