背景
GAIL算法存在的问题:
- 模态崩塌问题:指生成模型产生的生成样本塌缩于真实样本分布的某一模态下的子分布,而无法覆盖全部真实样本分布。
- 生成样本利用效率低:是GAIL假设策略为随机性策略并以无模型RL方法来学习策略。由于随机性策略采样动作的过程是不可微分的,因此反向传播的链式求导在策略模型万的动作节点处中断。在随机环境中,智能体的状态迁移过程是随机的。
InfoGAIL主要改进第一个问题,以自动驾驶为例,GAIL算法不能够很好处理不同驾驶风格的多专家数据场景。专家个体的不同,样本服从多个模态下的子分布,单一模态的假设不符合实际问题。
InfoGAIL
核心思想:InfoGAIL假设专家数据具有多个模态的分布,从专家数据中同时学习多种有效的模态,比如快速驾驶模态与安全驾驶模态,增加辅助网络用来对样本所属的模态类别进行分类。InfoGAIL将信息论中的互信息概念运用到GAIL模型中,通过最大化互信息的原来,能增强策略产生的样本与模态隐变量之间的相关性,进而实现无监督的多模态学习。
互信息表示一个随机变量x在给定另一变量y后所减少的不确定性或信息量。通俗来说,互信息表示x与y之间的相关性,互信息越大,两者越相关。公式表示为:
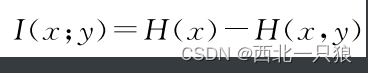
InfoGAIL在GAIL的基础上考虑最大化待学习策略产生的状态-动作与模态隐变量之前的互信息:
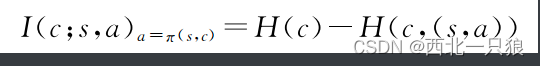
具体的目标函数由原始的GAIL的目标函数引入互信息的惩罚性形成:
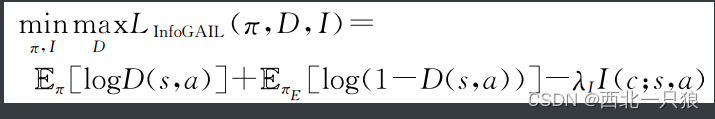
由于缺少模态标签知识,互信息中的交叉熵无法直接计算,参考InfoGANs,将互信息放松为变分下界,并用网络模型Y近似后验概率。
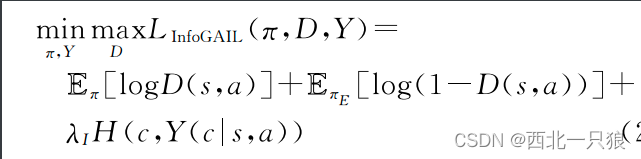
对比原始GAN、GAIL、InfoGAN
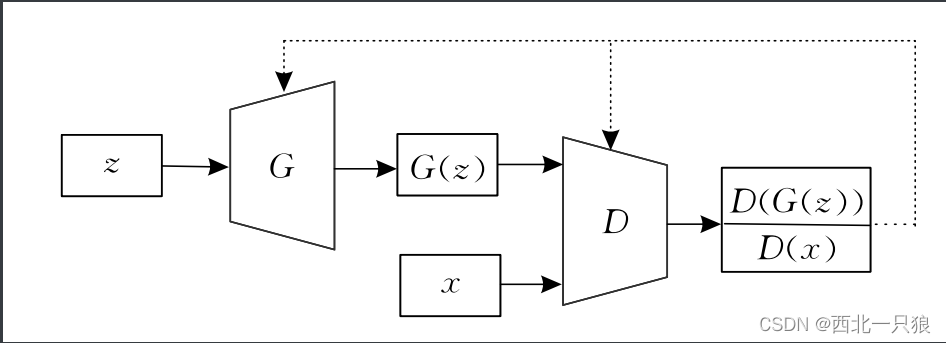
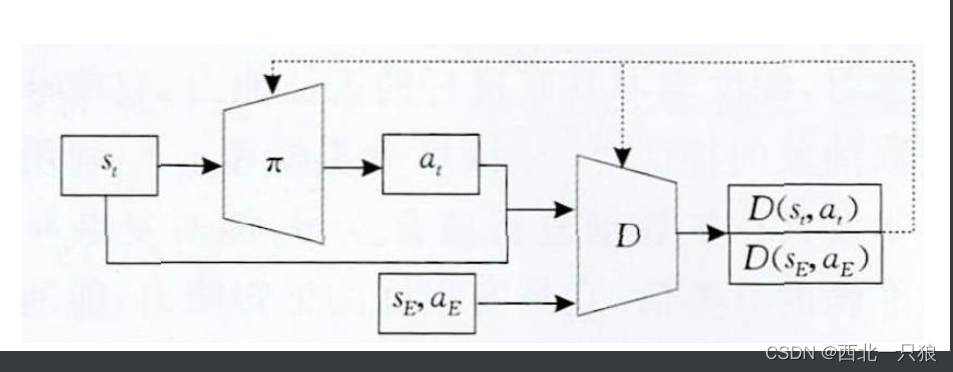
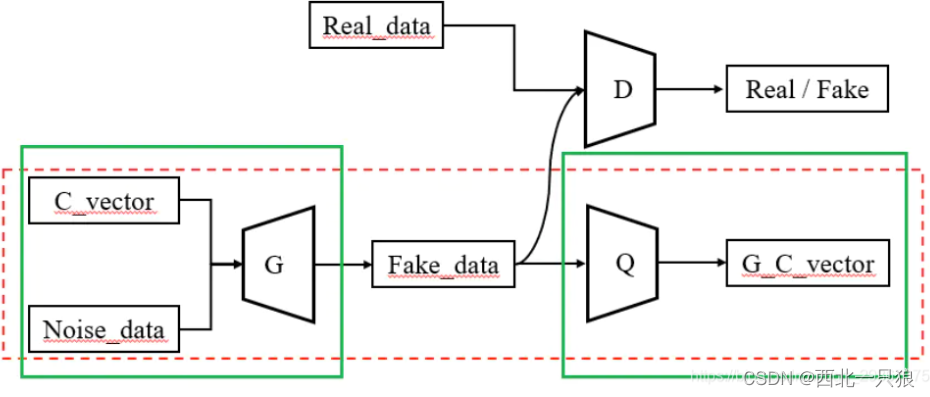
InfoGAIL的训练框架:
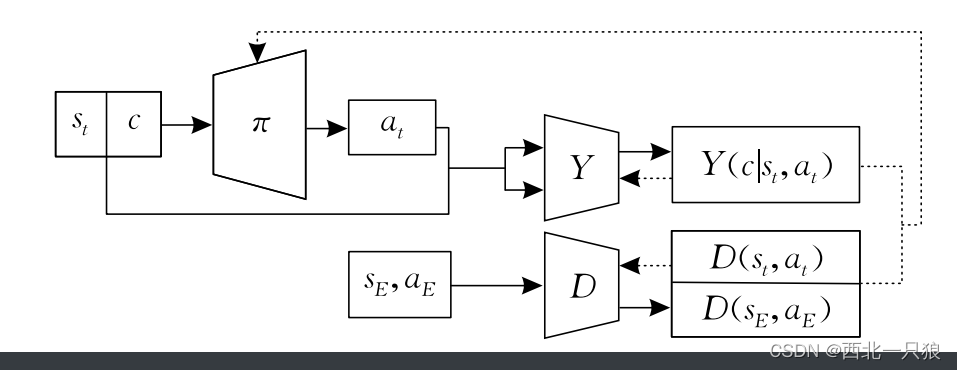
在InfoGAIL训练机制中,判别器D发挥着与原始GAIL中的D一样的功能,D引导π 产生的样本拟合专家样本分布.推断器Y以策略π 产生的(s,a)为输入,推断样本的后验概率.Y并不输入和处理专家样本.Y遵循互信息最大化的原理,不断改进自身的推断模型,从而解释出与π产生的样本相关程度最大的模态隐变量.Y引导策略产生与隐变量相关的状态-动作对.
除此之外还有两点优化:
1、Reward Augmentation :引入先验知识。考虑到专家策略本身是次优的,那么学习到的策略就到不了最优水平。引入一个基于状态的奖励函数:
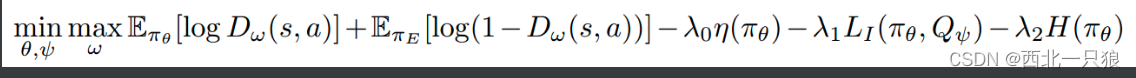
2、Improved Optimization:优化高维输入任务的表现及避免GAN网络的梯度消失问题,采用WGAN框架:
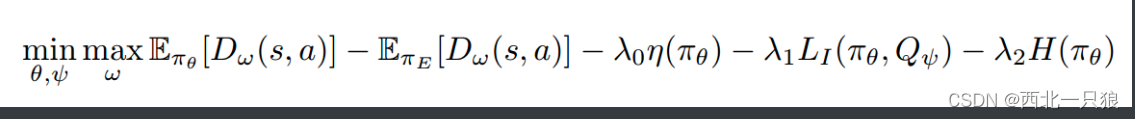
效果如下,BC算法的主要思想是直接克隆专家样本在各状态处的单步动作映射,BC会将细微的误差在序列的决策过程中逐步放大,GAIL算法假设所有的数据来源于一个专家,倾向于平均策略,InfoGAIL能够区分不同专家的行为:
