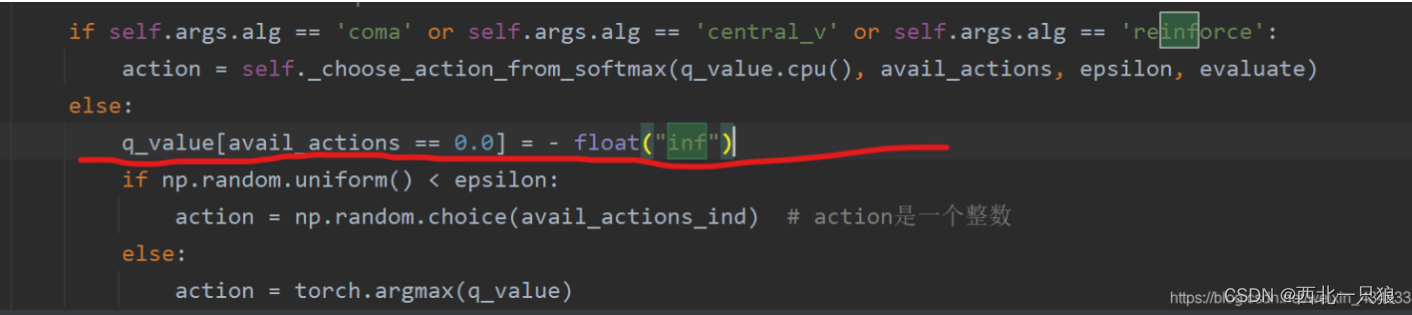
defforward(self, input_dict, state, seq_lens): # Extract the available actions tensor from the observation. avail_actions = input_dict["obs"]["avail_actions"] action_mask = input_dict["obs"]["action_mask"]
# Expand the model output to [BATCH, 1, EMBED_SIZE]. Note that the # avail actions tensor is of shape [BATCH, MAX_ACTIONS, EMBED_SIZE]. intent_vector = tf.expand_dims(action_embed, 1)
# Batch dot product => shape of logits is [BATCH, MAX_ACTIONS]. action_logits = tf.reduce_sum(avail_actions * intent_vector, axis=2)
# Mask out invalid actions (use tf.float32.min for stability) inf_mask = tf.maximum(tf.log(action_mask), tf.float32.min) return action_logits + inf_mask, state
# disable action masking --> will likely lead to invalid actions self.no_masking = False if"no_masking"in model_config["custom_model_config"]: self.no_masking = model_config["custom_model_config"]["no_masking"]
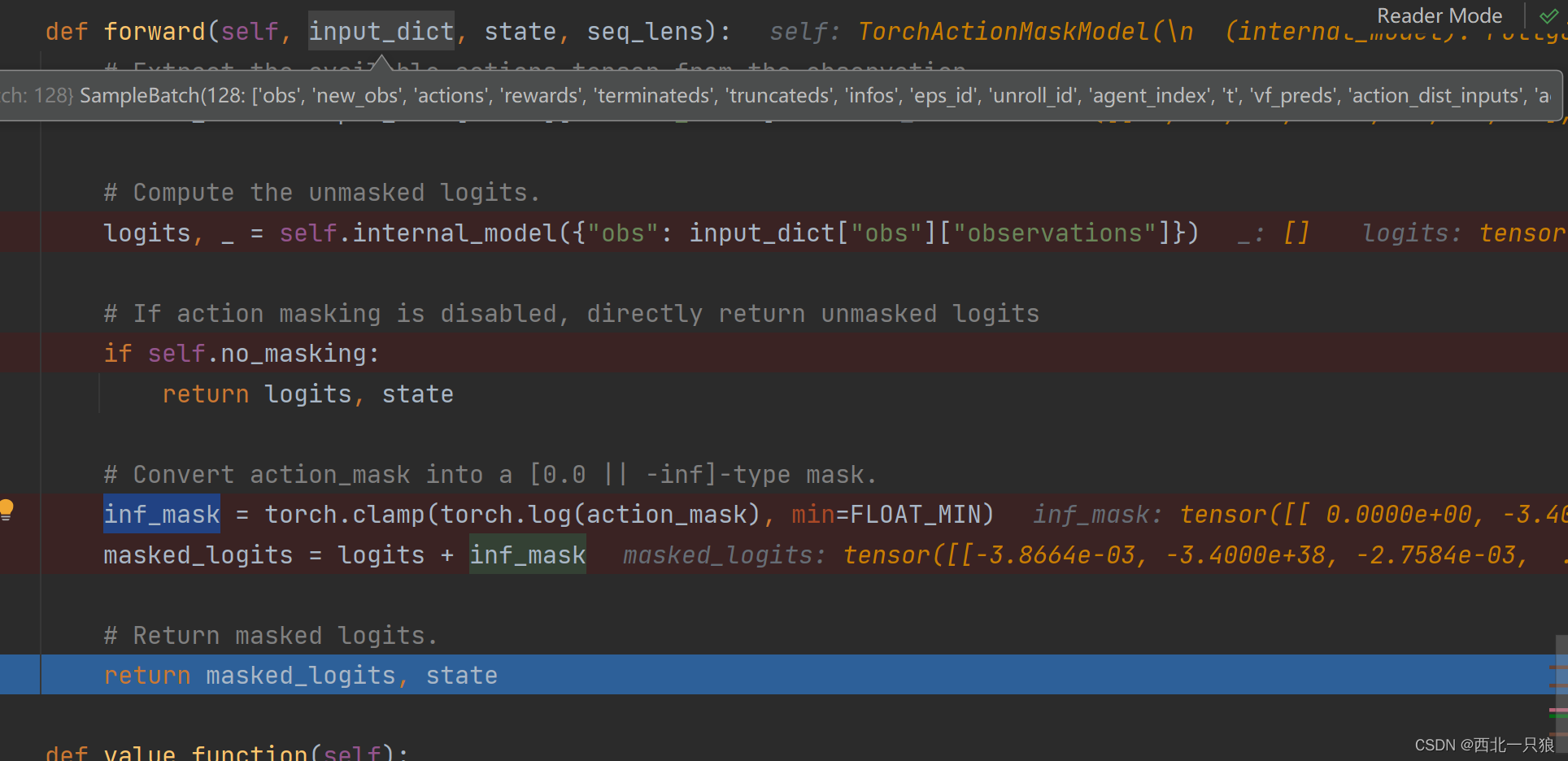
defforward(self, input_dict, state, seq_lens): # Extract the available actions tensor from the observation. action_mask = input_dict["obs"]["action_mask"]
# Compute the unmasked logits. logits, _ = self.internal_model({"obs": input_dict["obs"]["observations"]})
# If action masking is disabled, directly return unmasked logits ifself.no_masking: return logits, state
# Convert action_mask into a [0.0 || -inf]-type mask. inf_mask = torch.clamp(torch.log(action_mask), min=FLOAT_MIN) masked_logits = logits + inf_mask
# Return masked logits. return masked_logits, state