背景 Kubeflow 是 Google 推出的基于 kubernetes 环境下的机器学习组件,通过 Kubeflow 可以实现对 TFJob 等资源类型定义,可以像部署应用一样完成在 TFJob 分布式训练模型的过程。
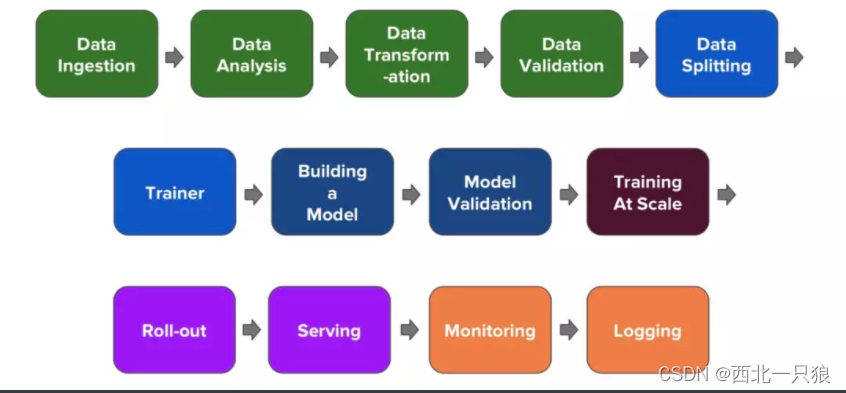
简单介绍下真正的机器学习模型服务上线都需要经历哪些阶段,如下图所示:
一个机器学习模型上线对外提供服务要经过:数据清洗验证,数据集切分, 训练,构建验证模型, 大规模训练,模型导出,模型服务上线, 日志监控等阶段。Tensorflow 等计算框架解决了最核心的部分问题,但是距离生产化,产品化,以及企业级机器学习项目开发,还有一段距离。比如: 数据收集, 数据清洗, 特征提取, 计算资源管理, 模型服务, 配置管理, 存储, 监控, 日志等等。
Kubeflow 诞生于2017年,Kubeflow项目是基于容器和Kubernetes构建,旨在为数据科学家、机器学习工程师、系统运维人员提供面向机器学习业务的敏捷部署、开发、训练、发布和管理平台。它利用了云原生技术的优势,让用户更快速、方便的部署、使用和管理当前最流行的机器学习软件。
Kubeflow特点:
基于k8s,具有云原生的特性:弹性伸缩、高可用、DevOps等
集成大量机器学习所用到的工具
原生的资源隔离
集群化自动化管理
计算资源(CPU/GPU)自动调度
对多种分布式存储的支持
集成较为成熟的监控,告警
将机器学习各个阶段涉及的组件以微服务的方式进行组合并以容器化的方式进行部署,提供整个流程各个系统的高可用及方便的进行扩展。
核心组件
jupyter 多租户 NoteBook 服务
Tensorflow/[PyTorch] 当前主要支持的机器学习引擎
Seldon 提供在 Kubernetes 上对机器学习模型的部署
TF-Serving 提供对 Tensorflow 模型的在线部署,支持版本控制及无需停止线上服务,切换模型等功能
Argo 基于 Kubernetes 的工作流引擎
Ambassador 对外提供统一服务的网关(API Gateway)
Istio 提供微服务的管理,Telemetry 收集
Ksonnet Kubeflow 使用 ksonnet 来向 kubernetes 集群部署需要的 k8s 资源
pipelines是 Kubeflow 社区新近开源的端到端的 ML/DL 工作流系统。实现了一个工作流模型。所谓工作流,或者称之为流水线(pipeline),可以将其当做一个有向无环图(DAG)
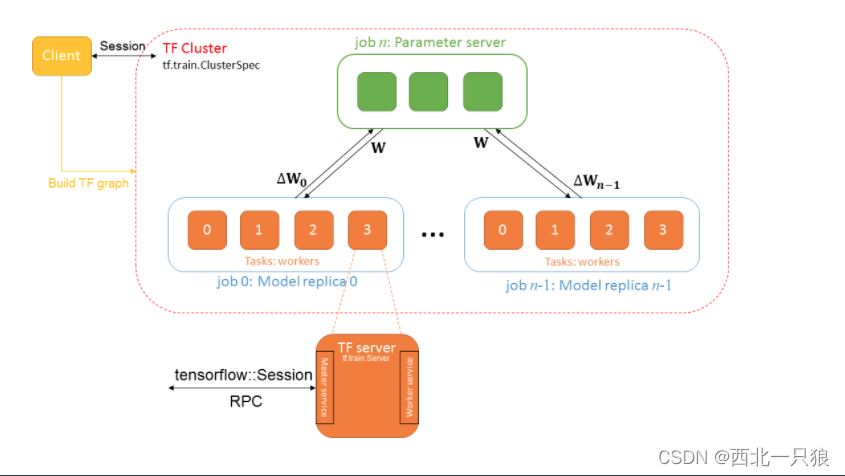
1、TFJob
TFJob 是将 tensorflow 的分布式架构基于 k8s 构建的一种CRD:
Chief 负责协调训练任务Ps 参数服务器,为模型的参数提供分布式的数据存储Worker 负责实际训练模型的任务. 在某些情况下 worker 0 可以充当Chief的责任。Evaluator 负责在训练过程中进行性能评估
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 apiVersion: kubeflow.org/v1beta2 kind: TFJob metadata: name: mnist-train namespace: kubeflow spec: tfReplicaSpecs: Chief: # 调度器 replicas: 1 template: spec: containers: - command: - /usr/bin/python - /opt/model.py env: - name: modelDir value: /mnt - name: exportDir value: /mnt/export image: mnist-test:v0.1 name: tensorflow volumeMounts: - mountPath: /mnt name: local-storage workingDir: /opt restartPolicy: OnFailure volumes: - name: local-storage persistentVolumeClaim: claimName: local-path-pvc Ps: # 参数服务器 replicas: 1 template: spec: containers: - command: - /usr/bin/python - /opt/model.py env: - name: modelDir value: /mnt - name: exportDir value: /mnt/export image: mnist-test:v0.1 name: tensorflow volumeMounts: - mountPath: /mnt name: local-storage workingDir: /opt restartPolicy: OnFailure volumes: - name: local-storage persistentVolumeClaim: claimName: local-path-pvc Worker: # 计算节点 replicas: 2 template: spec: containers: - command: - /usr/bin/python - /opt/model.py env: - name: modelDir value: /mnt - name: exportDir value: /mnt/export image: mnist-test:v0.1 name: tensorflow volumeMounts: - mountPath: /mnt name: local-storage workingDir: /opt restartPolicy: OnFailure volumes: - name: local-storage persistentVolumeClaim: claimName: local-path-pvc
2、tensorboard 训练可视化界面
挂载日志文件,创建 tensorboard 可视化服务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 apiVersion: v1 kind: Service metadata: name: tensorboard-tb namespace: kubeflow spec: ports: - name: http port: 8080 targetPort: 80 selector: app: tensorboard tb-job: tensorboard --- apiVersion: apps/v1beta1 kind: Deployment metadata: name: tensorboard-tb namespace: kubeflow spec: replicas: 1 template: metadata: labels: app: tensorboard tb-job: tensorboard name: tensorboard namespace: kubeflow spec: containers: - command: - /usr/local/bin/tensorboard - --logdir=/mnt - --port=80 env: - name: logDir value: /mnt image: tensorflow/tensorflow:1.11.0 name: tensorboard ports: - containerPort: 80 volumeMounts: - mountPath: /mnt name: local-storage serviceAccount: default-editor volumes: - name: local-storage persistentVolumeClaim: claimName: mnist-test-pvc
3、tf-serving
tenserflow serving 提供一个稳定的接口,供用户调用,来应用该模型,serving 通过模型文件直接创建模型即服务(Model as a service)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 apiVersion: v1 kind: Service metadata: labels: app: mnist name: mnist-service-local namespace: kubeflow spec: ports: - name: grpc-tf-serving port: 9000 targetPort: 9000 - name: http-tf-serving port: 8500 targetPort: 8500 selector: app: mnist type: ClusterIP --- apiVersion: extensions/v1beta1 kind: Deployment metadata: labels: app: mnist name: mnist-service-local namespace: kubeflow spec: template: metadata: labels: app: mnist version: v1 spec: containers: - args: - --port=9000 - --rest_api_port=8500 - --model_name=mnist - --model_base_path=/mnt/export command: - /usr/bin/tensorflow_model_server env: - name: modelBasePath value: /mnt/export image: tensorflow/serving:1.11.1 imagePullPolicy: IfNotPresent livenessProbe: initialDelaySeconds: 30 periodSeconds: 30 tcpSocket: port: 9000 name: mnist ports: - containerPort: 9000 - containerPort: 8500 resources: limits: cpu: "4" memory: 4Gi requests: cpu: "1" memory: 1Gi volumeMounts: - mountPath: /mnt name: local-storage
4、pipeline
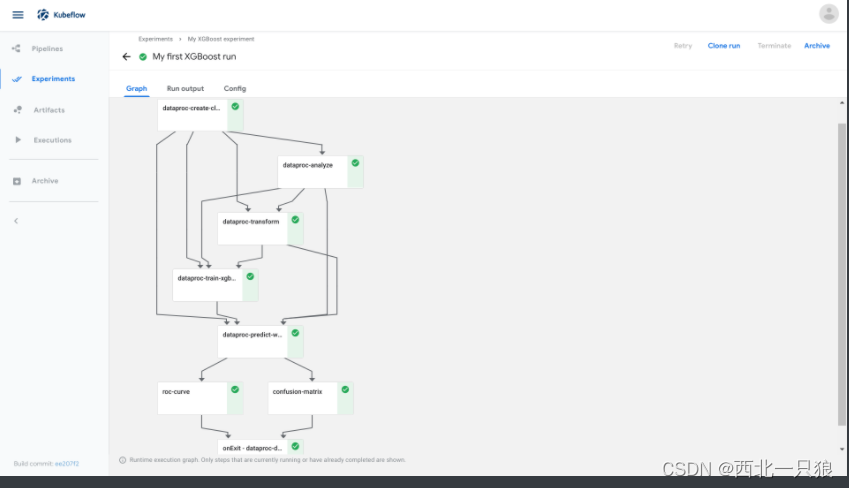
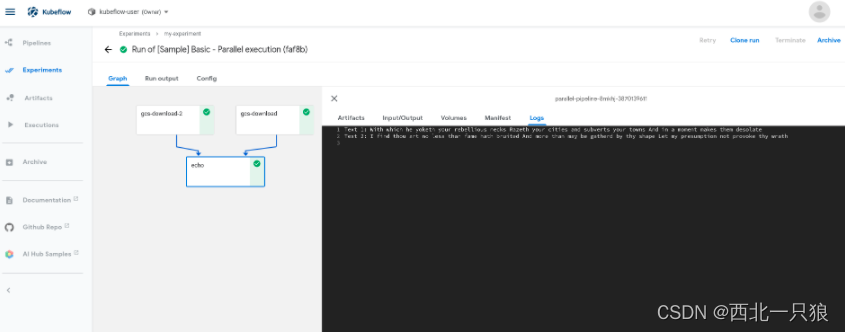
pipeline 是一个可视化的kubeflow任务工作流(Workflow),定义了一个有向无环图描述的流水线,流水线中每一步流程是由容器定义组成的组件。
运行步骤:
先要定义一个Experiment实验
然后发起任务,定义一个Pipeline
运行Pipeline实例
pipeline结构介绍
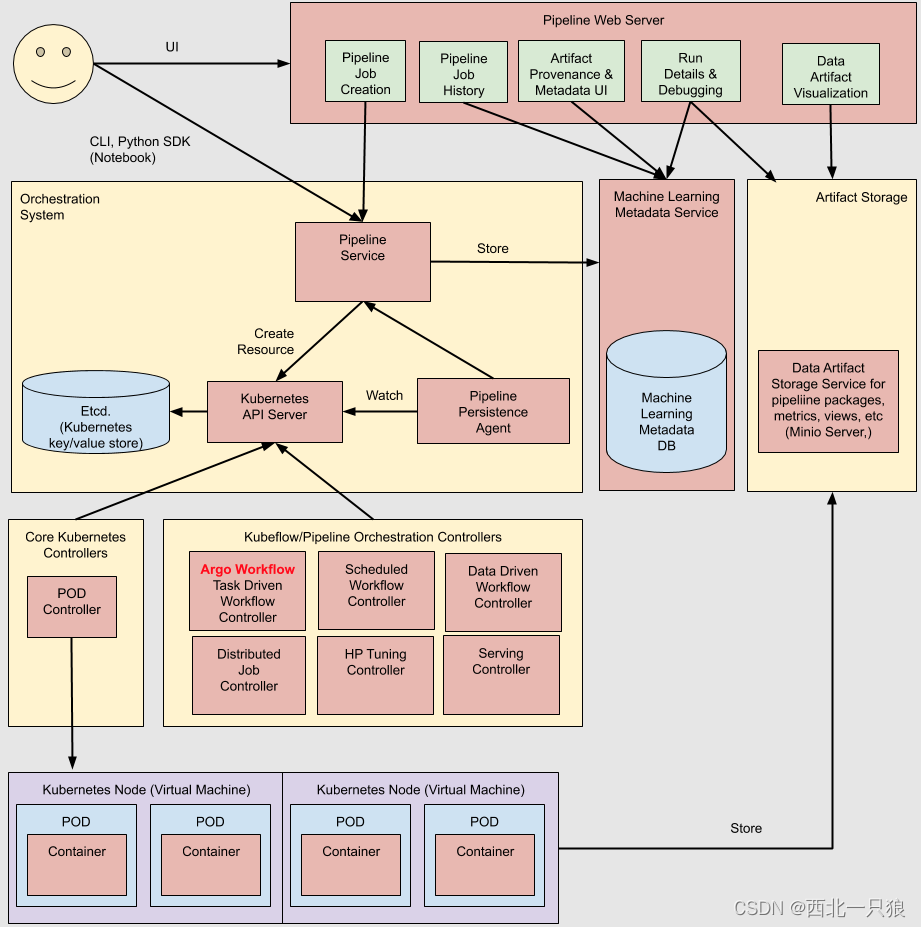
pipeline主要分为八部分:
Python SDK: 用于创建kubeflow pipeline 的DSL
DSL compiler: 将Python代码转换成YAML静态配置文件
Pipeline web server: pipeline的前端服务
Pipeline Service: pipeline的后端服务
Kubernetes resources: 创建CRDs运行pipeline
Machine learning metadata service: 用于存储任务流容器之间的数据交互(input/output)
Artifact storage: 用于存储 Metadata 和 Pipeline packages, views
Orchestration controllers:任务编排,比如Argo Workflow.
案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import kfpfrom kfp import dsldef gcs_download_op (url ): return dsl.ContainerOp( name='GCS - Download' , image='google/cloud-sdk:272.0.0' , command=['sh' , '-c' ], arguments=['gsutil cat $0 | tee $1' , url, '/tmp/results.txt' ], file_outputs={ 'data' : '/tmp/results.txt' , } ) def echo2_op (text1, text2 ): return dsl.ContainerOp( name='echo' , image='library/bash:4.4.23' , command=['sh' , '-c' ], arguments=['echo "Text 1: $0"; echo "Text 2: $1"' , text1, text2] ) @dsl.pipeline( name='Parallel pipeline' , description='Download two messages in parallel and prints the concatenated result.' def download_and_join ( url1='gs://ml-pipeline-playground/shakespeare1.txt' , url2='gs://ml-pipeline-playground/shakespeare2.txt' """A three-step pipeline with first two running in parallel.""" download1_task = gcs_download_op(url1) download2_task = gcs_download_op(url2) echo_task = echo2_op(download1_task.output, download2_task.output) if __name__ == '__main__' : kfp.compiler.Compiler().compile (download_and_join, __file__ + '.yaml' )
5、jupyter-notebook
jupyter 是最大限度的利用交互式的工作,他的主要工作体现利用交互式的操作帮助用户快速理解数据和测试评估模型。
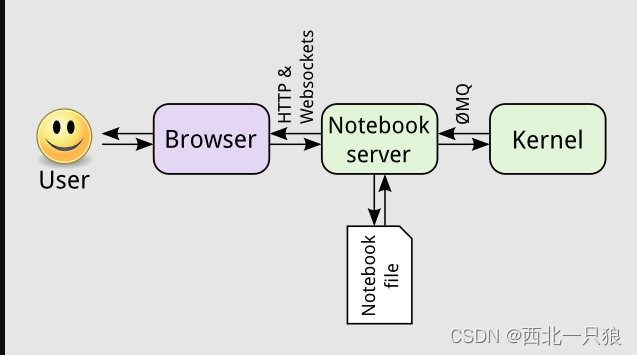
主要包括两个模块jupyter-web-app 和 notebook-controller, jupyter 架构:
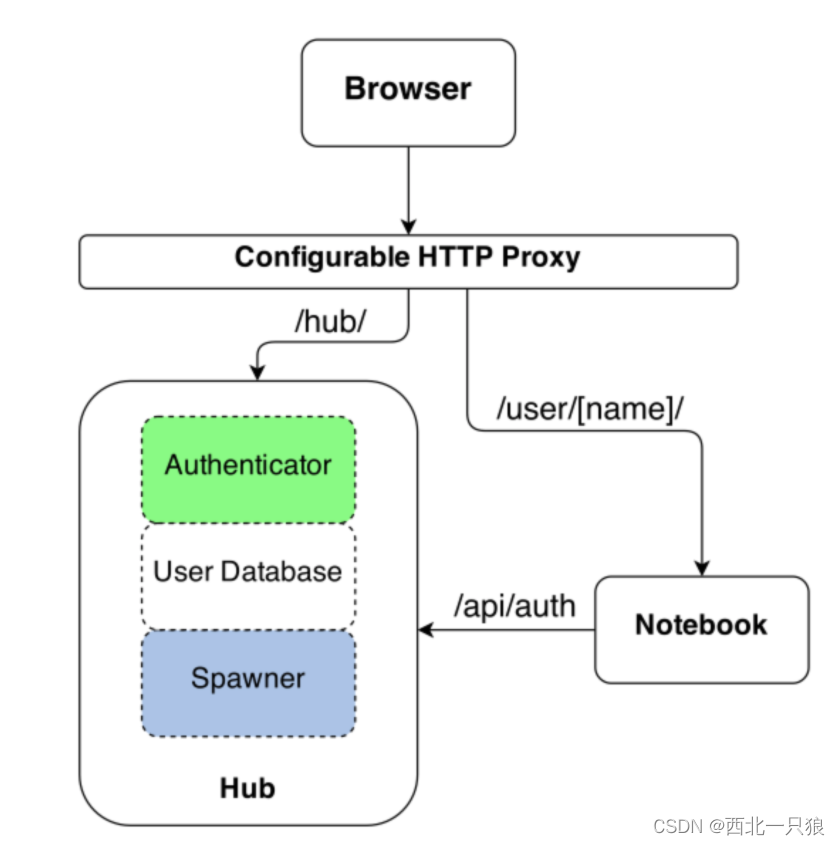
也可以用 jupyterhub 代替jupyter, jupyterhub提供了更多功能, jupyterhub 结构:
安装 准备工作:
1、配置docker访问外网代理
2、安装k8s集群(使用 Kubeadm 安装 Kubernetes 集群)
使用 kfctl 安装 Kubeflow:
安装 kustomize
1 2 curl -s "https://raw.githubusercontent.com/kubernetes-sigs/kustomize/master/hack/install_kustomize.sh" | bash mv kustomize /usr/local/bin/
安装 Kubefolow
确保有默认的 StorageClass
下载 kfctl
1 wget https://github.com/kubeflow/kubeflow/releases/download/v1.0/kfctl_v1.0-0-g94c35cf_linux.tar.gz
1 2 tar -xvf *_linux.tar.gz mv kfctl /usr/local/bin/
安装环境变量
1 2 3 4 5 6 7 mkdir /home/kubeflowexport KF_NAME="mykubeflow" export BASE_DIR="/home/kubeflow" export KF_DIR=${BASE_DIR} /${KF_NAME} export CONFIG_URI="https://raw.githubusercontent.com/kubeflow/manifests/v1.0-branch/kfdef/kfctl_k8s_istio.v1.0.2.yaml"
开始安装
1 2 3 mkdir -p ${KF_DIR} cd ${KF_DIR} kfctl apply -V -f ${CONFIG_URI}
1 kubectl -n kubeflow get pod --watch
查看 UI 页面
Kubeflow 通过 istio-ingressgateway 提供访问入口。由于没有 LoadBalancer ,这里将服务的 type 改为 NodePort ,执行命令:
1 for i in 'istio-ingressgateway' ; do kubectl patch service $i -p '{"spec":{"type":"NodePort"}}' -n istio-system; done
查看访问端口:
1 kubectl get svc -n istio-system | grep istio-ingressgateway
打开页面,http://{HOST_IP}:31380
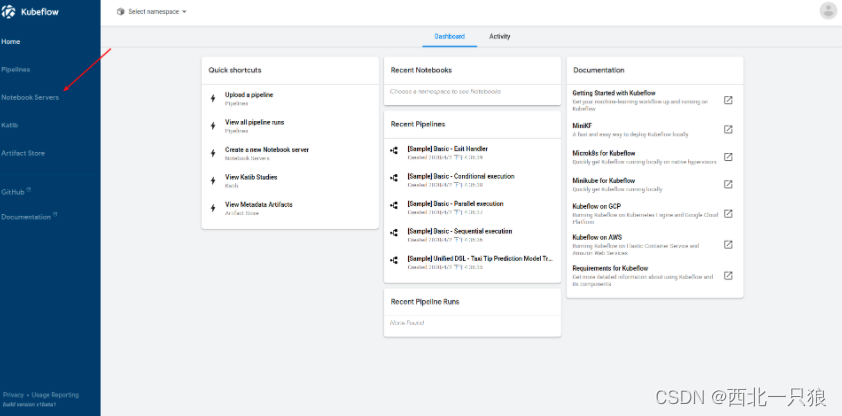
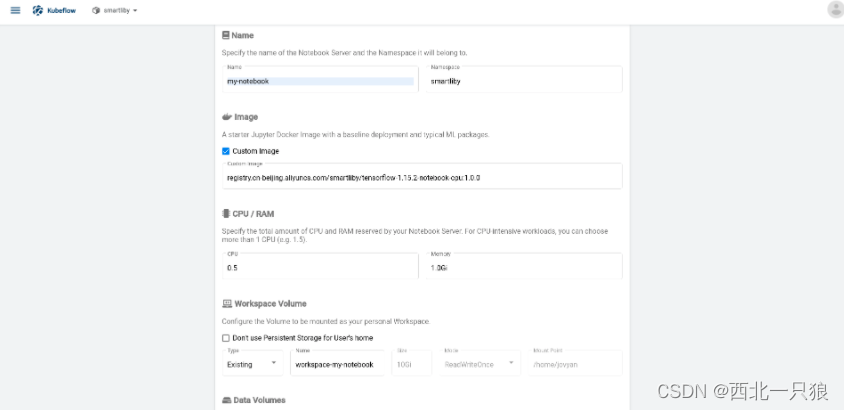
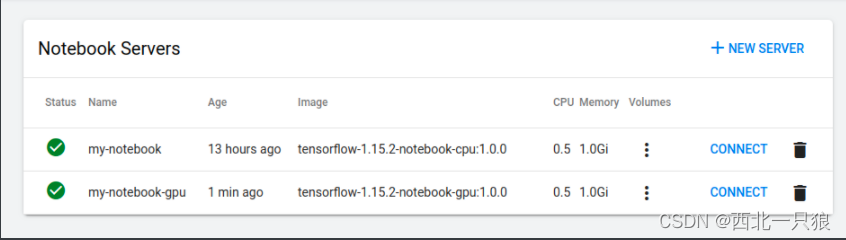
创建Jupyter notebook server
点击连接之后就可以跑模型训练了
测试Jupyter
创建Python 3 notebook,执行如下代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from tensorflow.examples.tutorials.mnist import input_datamnist = input_data.read_data_sets("MNIST_data/" , one_hot=True ) import tensorflow as tfx = tf.placeholder(tf.float32, [None , 784 ]) W = tf.Variable(tf.zeros([784 , 10 ])) b = tf.Variable(tf.zeros([10 ])) y = tf.nn.softmax(tf.matmul(x, W) + b) y_ = tf.placeholder(tf.float32, [None , 10 ]) cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1 ])) train_step = tf.train.GradientDescentOptimizer(0.05 ).minimize(cross_entropy) sess = tf.InteractiveSession() tf.global_variables_initializer().run() for _ in range (1000 ): batch_xs, batch_ys = mnist.train.next_batch(100 ) sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys}) correct_prediction = tf.equal(tf.argmax(y,1 ), tf.argmax(y_,1 )) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) print ("Accuracy: " , sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
运行结果如下
测试pipelines