import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers
# Define Sequential model with 3 layers model = keras.Sequential( [ layers.Dense(2, activation="relu", name="layer1"), layers.Dense(3, activation="relu", name="layer2"), layers.Dense(4, name="layer3"), ] ) # Call model on a test input x = tf.ones((3, 3)) y = model(x)
from tensorflow import keras from tensorflow.keras import layers
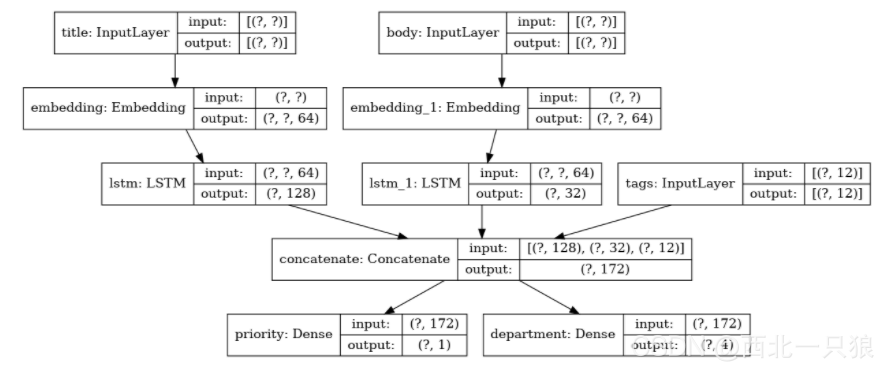
num_tags = 12# Number of unique issue tags num_words = 10000# Size of vocabulary obtained when preprocessing text data num_departments = 4# Number of departments for predictions
# Embed each word in the title into a 64-dimensional vector title_features = layers.Embedding(num_words, 64)(title_input) # Embed each word in the text into a 64-dimensional vector body_features = layers.Embedding(num_words, 64)(body_input)
# Reduce sequence of embedded words in the title into a single 128-dimensional vector title_features = layers.LSTM(128)(title_features) # Reduce sequence of embedded words in the body into a single 32-dimensional vector body_features = layers.LSTM(32)(body_features)
# Merge all available features into a single large vector via concatenation x = layers.concatenate([title_features, body_features, tags_input])
# Stick a logistic regression for priority prediction on top of the features priority_pred = layers.Dense(1, name="priority")(x) # Stick a department classifier on top of the features department_pred = layers.Dense(num_departments, name="department")(x)
# Instantiate an end-to-end model predicting both priority and department model = keras.Model( inputs=[title_input, body_input, tags_input], outputs=[priority_pred, department_pred], )
from tensorflow import keras from tensorflow.keras import layers
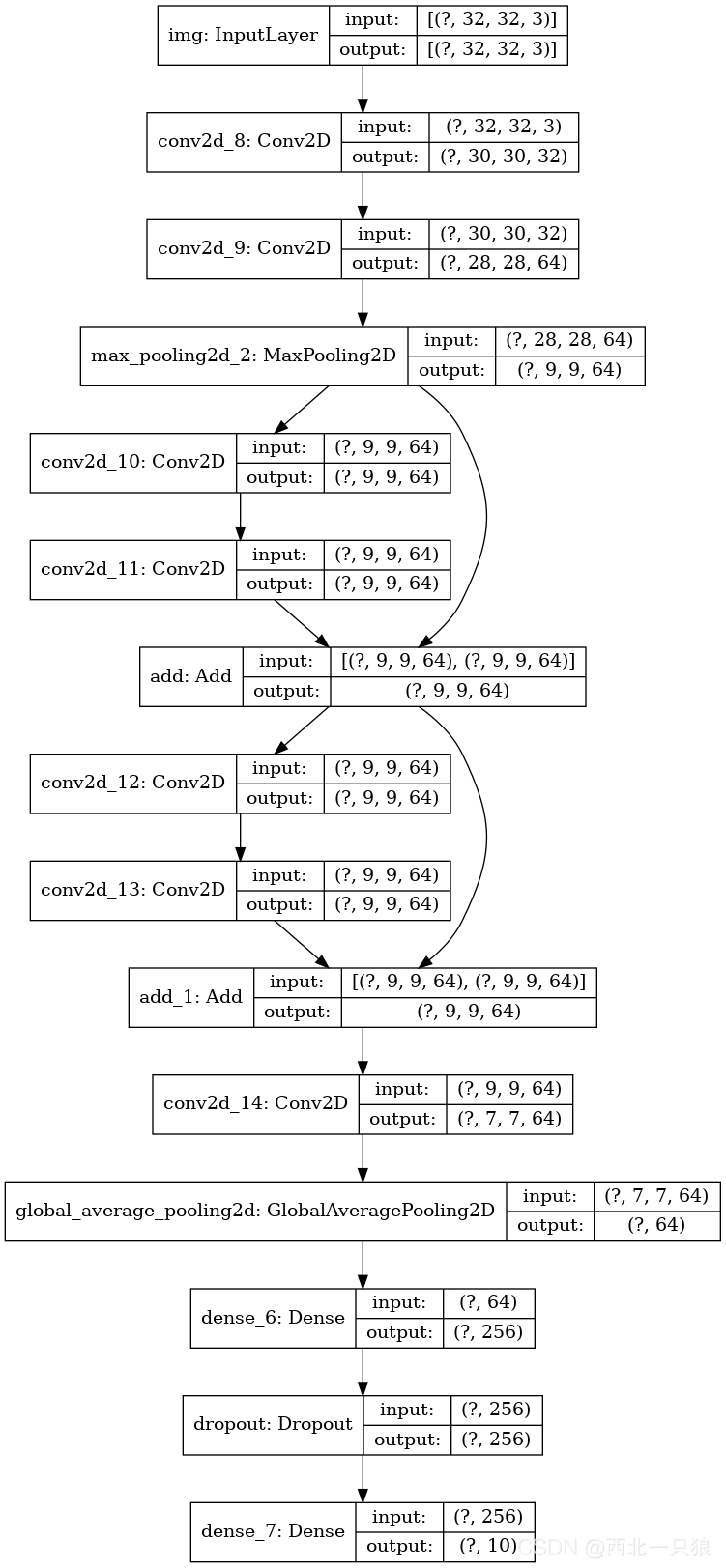
inputs = keras.Input(shape=(32, 32, 3), name="img") x = layers.Conv2D(32, 3, activation="relu")(inputs) x = layers.Conv2D(64, 3, activation="relu")(x) block_1_output = layers.MaxPooling2D(3)(x)
x = layers.Conv2D(64, 3, activation="relu", padding="same")(block_1_output) x = layers.Conv2D(64, 3, activation="relu", padding="same")(x) block_2_output = layers.add([x, block_1_output])
x = layers.Conv2D(64, 3, activation="relu", padding="same")(block_2_output) x = layers.Conv2D(64, 3, activation="relu", padding="same")(x) block_3_output = layers.add([x, block_2_output])
x = layers.Conv2D(64, 3, activation="relu")(block_3_output) x = layers.GlobalAveragePooling2D()(x) x = layers.Dense(256, activation="relu")(x) x = layers.Dropout(0.5)(x) outputs = layers.Dense(10)(x)
model = keras.Model(inputs, outputs, name="toy_resnet") model.summary()
model.compile( optimizer=keras.optimizers.RMSprop(1e-3), loss=keras.losses.CategoricalCrossentropy(from_logits=True), metrics=["acc"], ) # We restrict the data to the first 1000 samples so as to limit execution time # on Colab. Try to train on the entire dataset until convergence! model.fit(x_train[:1000], y_train[:1000], batch_size=64, epochs=1, validation_split=0.2)
函数式 API 的另一个很好的用途是使用共享层的模型。共享层是在同一个模型中多次重用的层实例,它们会学习与层计算图中的多个路径相对应的特征。
要在函数式 API 中共享层,请多次调用同一个层实例。例如,下面是一个在两个不同文本输入之间共享的 Embedding 层:
1 2 3 4 5 6 7 8 9 10 11 12
# Embedding for 1000 unique words mapped to 128-dimensional vectors shared_embedding = layers.Embedding(1000, 128)
# Variable-length sequence of integers text_input_a = keras.Input(shape=(None,), dtype="int32")
# Variable-length sequence of integers text_input_b = keras.Input(shape=(None,), dtype="int32")
# Reuse the same layer to encode both inputs encoded_input_a = shared_embedding(text_input_a) encoded_input_b = shared_embedding(text_input_b)
在函数式 API 或模型子类化之间进行选择并非是让您作出二选一的决定而将您限制在某一类模型中。tf.keras API 中的所有模型都可以彼此交互,无论它们是 Sequential 模型、函数式模型,还是从头开始编写的子类化模型。
from tensorflow import keras from tensorflow.keras import layers import tensorflow as tf
units = 32 timesteps = 10 input_dim = 5
# Define a Functional model inputs = keras.Input((None, units)) x = layers.GlobalAveragePooling1D()(inputs) outputs = layers.Dense(1)(x) model = keras.Model(inputs, outputs)
classCustomRNN(layers.Layer): def__init__(self): super(CustomRNN, self).__init__() self.units = units self.projection_1 = layers.Dense(units=units, activation="tanh") self.projection_2 = layers.Dense(units=units, activation="tanh") # Our previously-defined Functional model self.classifier = model
defcall(self, inputs): outputs = [] state = tf.zeros(shape=(inputs.shape[0], self.units)) for t inrange(inputs.shape[1]): x = inputs[:, t, :] h = self.projection_1(x) y = h + self.projection_2(state) state = y outputs.append(y) features = tf.stack(outputs, axis=1) print(features.shape) returnself.classifier(features)
print("Fit model on training data") history = model.fit( x_train, y_train, batch_size=64, epochs=2, # We pass some validation for # monitoring validation loss and metrics # at the end of each epoch validation_data=(x_val, y_val), )
通过 evaluate() 在测试数据上评估模型:
1 2 3 4 5 6 7 8 9 10
# Evaluate the model on the test data using `evaluate` print("Evaluate on test data") results = model.evaluate(x_test, y_test, batch_size=128) print("test loss, test acc:", results)
# Generate predictions (probabilities -- the output of the last layer) # on new data using `predict` print("Generate predictions for 3 samples") predictions = model.predict(x_test[:3]) print("predictions shape:", predictions.shape)
使用预处理层
1 2 3 4 5 6 7 8 9 10
import numpy as np from tensorflow.keras.layers.experimental import preprocessing
from tensorflow import keras from tensorflow.keras import layers
model = keras.Sequential() # Add an Embedding layer expecting input vocab of size 1000, and # output embedding dimension of size 64. model.add(layers.Embedding(input_dim=1000, output_dim=64))
# Add a LSTM layer with 128 internal units. model.add(layers.LSTM(128))
# Add a Dense layer with 10 units. model.add(layers.Dense(10))
model.summary()
双向 RNN
1 2 3 4 5 6 7 8 9 10 11 12
from tensorflow import keras from tensorflow.keras import layers
# By default, this will pad using 0s; it is configurable via the # "value" parameter. # Note that you could "pre" padding (at the beginning) or # "post" padding (at the end). # We recommend using "post" padding when working with RNN layers # (in order to be able to use the # CuDNN implementation of the layers). padded_inputs = tf.keras.preprocessing.sequence.pad_sequences( raw_inputs, padding="post" ) print(padded_inputs) # [[ 711 632 71 0 0 0] # [ 73 8 3215 55 927 0] # [ 83 91 1 645 1253 927]]
# Make a model with 2 layers layer1 = keras.layers.Dense(3, activation="relu") layer2 = keras.layers.Dense(3, activation="sigmoid") model = keras.Sequential([keras.Input(shape=(3,)), layer1, layer2])
# Freeze the first layer layer1.trainable = False
# Keep a copy of the weights of layer1 for later reference initial_layer1_weights_values = layer1.get_weights()
# Train the model model.compile(optimizer="adam", loss="mse") model.fit(np.random.random((2, 3)), np.random.random((2, 3)))
# Check that the weights of layer1 have not changed during training final_layer1_weights_values = layer1.get_weights() np.testing.assert_allclose( initial_layer1_weights_values[0], final_layer1_weights_values[0] ) np.testing.assert_allclose( initial_layer1_weights_values[1], final_layer1_weights_values[1] )
base_model = keras.applications.Xception( weights='imagenet', # Load weights pre-trained on ImageNet. input_shape=(150, 150, 3), include_top=False) # Do not include the ImageNet classifier at the top. # 冻结该基础模型 base_model.trainable = False inputs = keras.Input(shape=(150, 150, 3)) # We make sure that the base_model is running in inference mode here, # by passing `training=False`. This is important for fine-tuning, as you will # learn in a few paragraphs. x = base_model(inputs, training=False) # Convert features of shape `base_model.output_shape[1:]` to vectors x = keras.layers.GlobalAveragePooling2D()(x) # A Dense classifier with a single unit (binary classification) outputs = keras.layers.Dense(1)(x) model = keras.Model(inputs, outputs) # 在新数据上训练该模型 model.compile(optimizer=keras.optimizers.Adam(), loss=keras.losses.BinaryCrossentropy(from_logits=True), metrics=[keras.metrics.BinaryAccuracy()]) model.fit(new_dataset, epochs=20, callbacks=..., validation_data=...)
# Unfreeze the base model base_model.trainable = True
# It's important to recompile your model after you make any changes # to the `trainable` attribute of any inner layer, so that your changes # are take into account model.compile(optimizer=keras.optimizers.Adam(1e-5), # Very low learning rate loss=keras.losses.BinaryCrossentropy(from_logits=True), metrics=[keras.metrics.BinaryAccuracy()])
# Train end-to-end. Be careful to stop before you overfit! model.fit(new_dataset, epochs=10, callbacks=..., validation_data=...)