Q-Learning
Q-Learning 是一个强化学习中一个很经典的算法,其出发点很简单,就是用一张表存储在各个状态下执行各种动作能够带来的 reward,如下表表示了有两个状态 s1,s2s1,s2,每个状态下有两个动作 a1,a2a1,a2, 表格里面的值表示 reward

这个表示实际上就叫做 Q-Table,里面的每个值定义为 Q(s,a)Q(s,a), 表示在状态 ss 下执行动作 aa 所获取的reward,那么选择的时候可以采用一个贪婪的做法,即选择价值最大的那个动作去执行。 Q-Table 要如何获取?答案是随机初始化,然后通过不断执行动作获取环境的反馈并通过算法更新 Q-Table。
Deep Q Network
DQN与Q-leanring类似都是基于值迭代的算法,但是在普通的Q-learning中,当状态和动作空间是离散且维数不高时可使用Q-Table储存每个状态动作对的Q值,而当状态和动作空间是高维连续时,使用Q-Table不动作空间和状态太大十分困难。
所以可以把Q-table更新转化为一函数拟合问题,通过拟合一个函数function来代替Q-table产生Q值,使得相近的状态得到相近的输出动作。因此我们可以想到深度神经网络对复杂特征的提取有很好效果,所以可以将DeepLearning与Reinforcement Learning结合。这就成为了DQN。
通过 NN 预测出Q(s2, a1) 和 Q(s2,a2) 的值, 这就是 Q 估计. 然后我们选取 Q 估计中最大值的动作来换取环境中的奖励 reward. 而 Q 现实中也包含从神经网络分析出来的两个 Q 估计值, 不过这个 Q 估计是针对于下一步在 s’ 的估计。
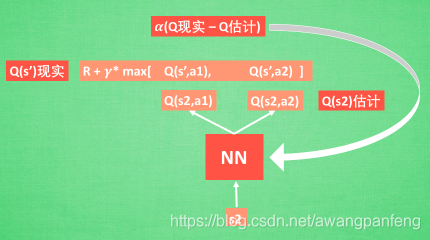
DQN 的实现会遇到许多困难,其中最显著的就是:



 ”来进行填充的。
”来进行填充的。