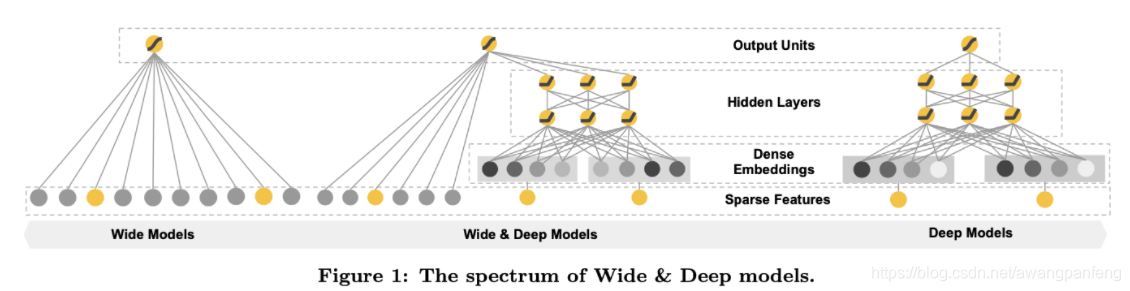
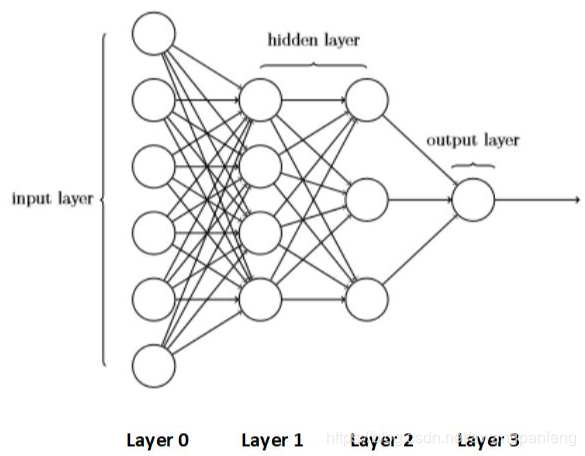
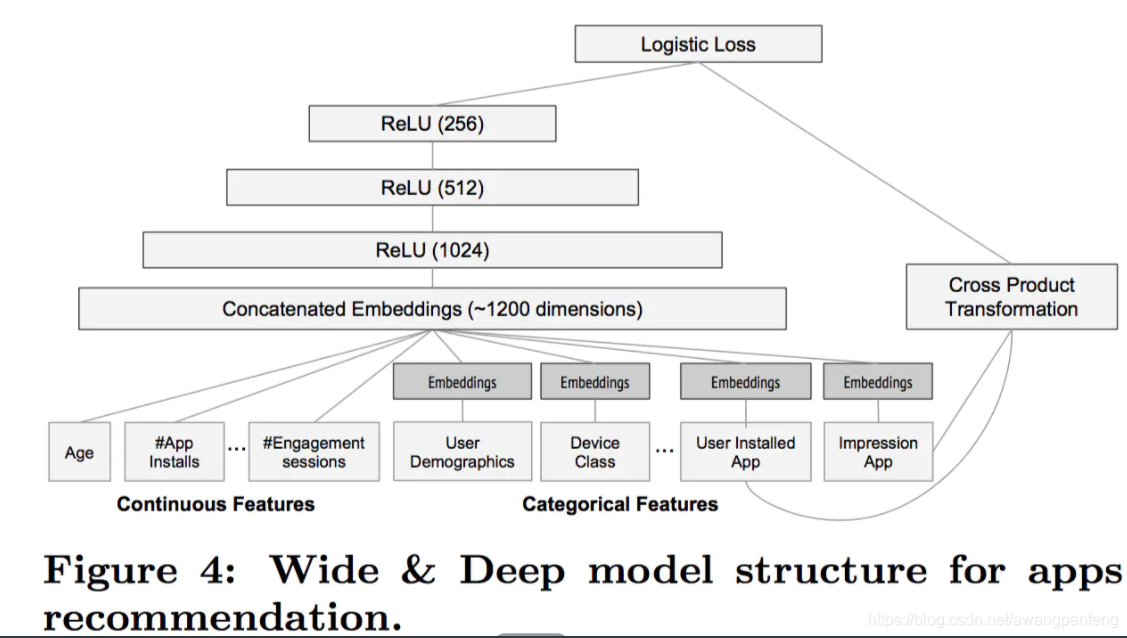
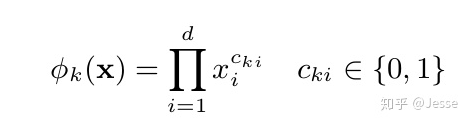1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
| import tensorflow as tf
from absl import flags
from absl import app
# 1. 最基本的特征:
# Continuous columns. Wide和Deep组件都会用到。
age = tf.feature_column.numeric_column('age')
education_num = tf.feature_column.numeric_column('education_num')
capital_gain = tf.feature_column.numeric_column('capital_gain')
capital_loss = tf.feature_column.numeric_column('capital_loss')
hours_per_week = tf.feature_column.numeric_column('hours_per_week')
# 离散特征
education = tf.feature_column.categorical_column_with_vocabulary_list(
'education', [
'Bachelors', 'HS-grad', '11th', 'Masters', '9th', 'Some-college',
'Assoc-acdm', 'Assoc-voc', '7th-8th', 'Doctorate', 'Prof-school',
'5th-6th', '10th', '1st-4th', 'Preschool', '12th'])
marital_status = tf.feature_column.categorical_column_with_vocabulary_list(
'marital_status', [
'Married-civ-spouse', 'Divorced', 'Married-spouse-absent',
'Never-married', 'Separated', 'Married-AF-spouse', 'Widowed'])
relationship = tf.feature_column.categorical_column_with_vocabulary_list(
'relationship', [
'Husband', 'Not-in-family', 'Wife', 'Own-child', 'Unmarried',
'Other-relative'])
workclass = tf.feature_column.categorical_column_with_vocabulary_list(
'workclass', [
'Self-emp-not-inc', 'Private', 'State-gov', 'Federal-gov',
'Local-gov', '?', 'Self-emp-inc', 'Without-pay', 'Never-worked'])
# 展示一下这个API
occupation = tf.feature_column.categorical_column_with_hash_bucket(
'occupation', hash_bucket_size=1000
)
# Transformations
age_buckets = tf.feature_column.bucketized_column(
age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65]
)
# 2. The Wide Model: Linear Model with CrossedFeatureColumns
"""
The wide model is a linear model with a wide set of *sparse and crossed feature* columns
Wide部分用了一个规范化后的连续特征age_buckets,其他的连续特征没有使用
"""
base_columns = [
# 全是离散特征
education, marital_status, relationship, workclass, occupation,
age_buckets,
]
crossed_columns = [
tf.feature_column.crossed_column(
['education', 'occupation'], hash_bucket_size=1000),
tf.feature_column.crossed_column(
[age_buckets, 'education', 'occupation'], hash_bucket_size=1000
)
]
# 3. The Deep Model: Neural Network with Embeddings
"""
1. Sparse Features -> Embedding vector -> 串联(Embedding vector, 连续特征) -> 输入到Hidden Layer
2. Embedding Values随机初始化
3. 另外一种处理离散特征的方法是:one-hot or multi-hot representation. 但是仅仅适用于维度较低的,embedding是更加通用的做法
4. embedding_column(embedding);indicator_column(multi-hot);
"""
deep_columns = [
age,
education_num,
capital_gain,
capital_loss,
hours_per_week,
tf.feature_column.indicator_column(workclass),
tf.feature_column.indicator_column(education),
tf.feature_column.indicator_column(marital_status),
tf.feature_column.indicator_column(relationship),
# To show an example of embedding
tf.feature_column.embedding_column(occupation, dimension=8)
]
model_dir = './model/wide_deep'
# 4. Combine Wide & Deep:wide基础上组合Deep
model = tf.estimator.DNNLinearCombinedClassifier(
model_dir=model_dir,
linear_feature_columns=base_columns + crossed_columns,
dnn_feature_columns=deep_columns,
dnn_hidden_units=[100, 50]
)
# 5. Train & Evaluate:训练和评估
_CSV_COLUMNS = [
'age', 'workclass', 'fnlwgt', 'education', 'education_num',
'marital_status', 'occupation', 'relationship', 'race', 'gender',
'capital_gain', 'capital_loss', 'hours_per_week', 'native_country',
'income_bracket'
]
_CSV_COLUMN_DEFAULTS = [[0], [''], [0], [''], [0], [''], [''], [''], [''], [''],
[0], [0], [0], [''], ['']]
_NUM_EXAMPLES = {
'train': 32561,
'validation': 16281,
}
def input_fn(data_file, num_epochs, shuffle, batch_size):
"""为Estimator创建一个input function"""
assert tf.gfile.Exists(data_file), "{0} not found.".format(data_file)
def parse_csv(line):
print("Parsing", data_file)
# tf.decode_csv会把csv文件转换成很a list of Tensor,一列一个。record_defaults用于指明每一列的缺失值用什么填充
columns = tf.decode_csv(line, record_defaults=_CSV_COLUMN_DEFAULTS)
features = dict(zip(_CSV_COLUMNS, columns))
labels = features.pop('income_bracket')
return features, tf.equal(labels, '>50K') # tf.equal(x, y) 返回一个bool类型Tensor, 表示x == y, element-wise
dataset = tf.data.TextLineDataset(data_file) \
.map(parse_csv, num_parallel_calls=5)
if shuffle:
dataset = dataset.shuffle(buffer_size=_NUM_EXAMPLES['train'] + _NUM_EXAMPLES['validation'])
dataset = dataset.repeat(num_epochs)
dataset = dataset.batch(batch_size)
iterator = dataset.make_one_shot_iterator()
batch_features, batch_labels = iterator.get_next()
return batch_features, batch_labels
# Train + Eval
train_epochs = 6
epochs_per_eval = 2
batch_size = 40
train_file = './data/adult.data'
test_file = './data/adult.test'
for n in range(train_epochs // epochs_per_eval):
model.train(input_fn=lambda: input_fn(train_file, epochs_per_eval, True, batch_size))
results = model.evaluate(input_fn=lambda: input_fn(
test_file, 1, False, batch_size))
# Display Eval results
print("Results at epoch {0}".format((n + 1) * epochs_per_eval))
print('-' * 30)
for key in sorted(results):
print("{0:20}: {1:.4f}".format(key, results[key]))
|