浏览器抓包,修改参数上报。
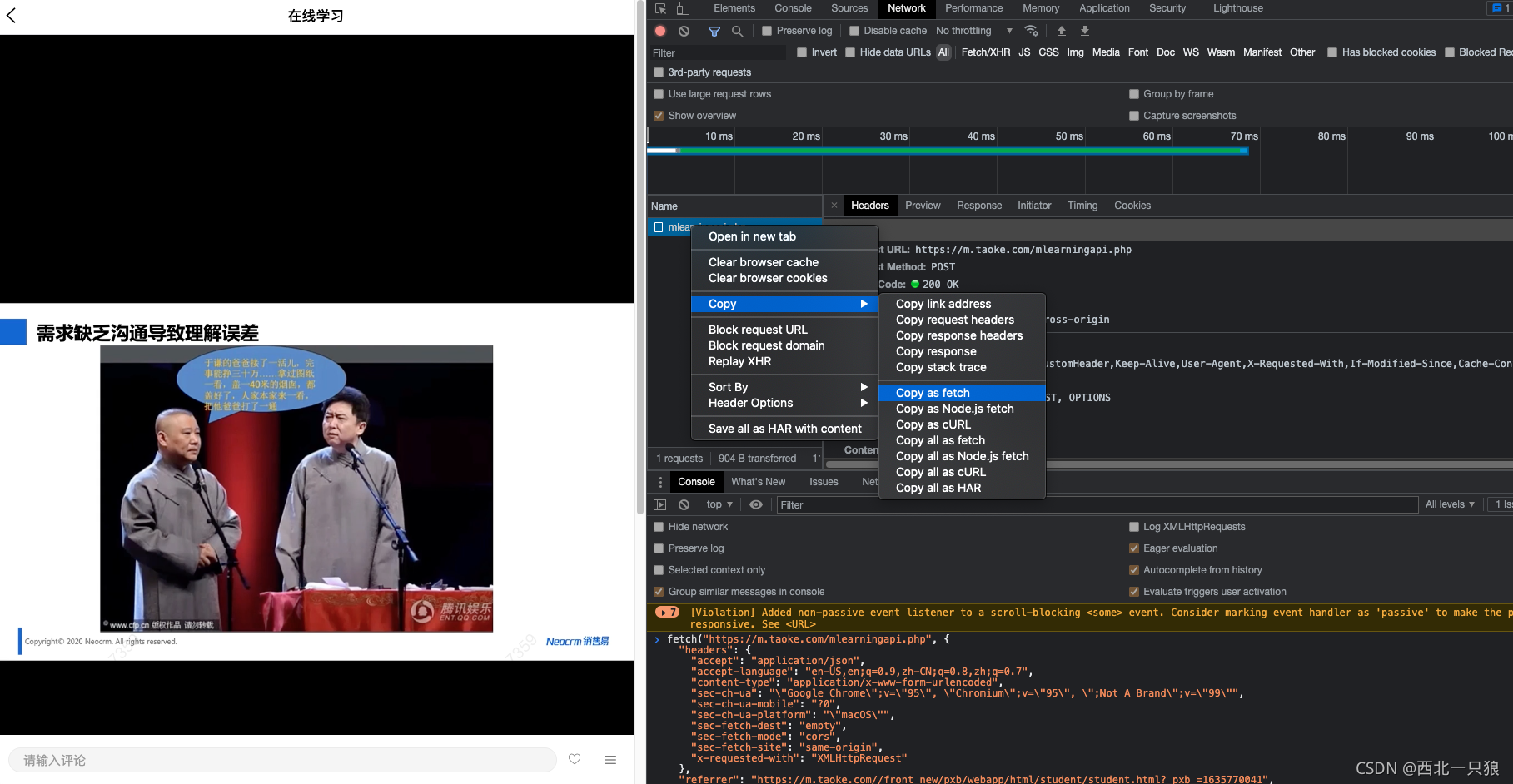
前端无限断点调试。
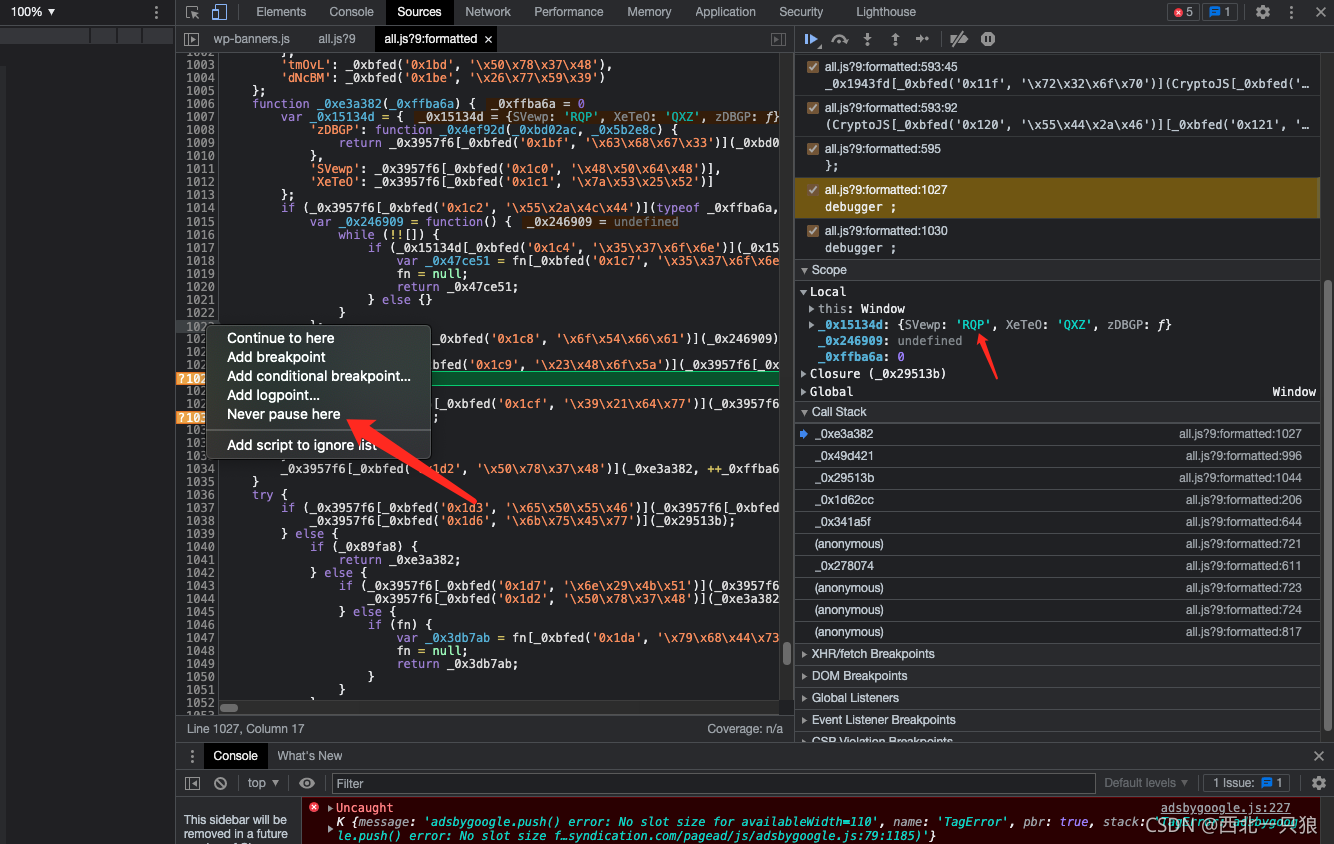
抓包替换JS。
Convert curl commands to Python, JavaScript, PHP, R, Go, Rust, Elixir, Java, MATLAB, Ansible URI, Strest, Dart or JSON
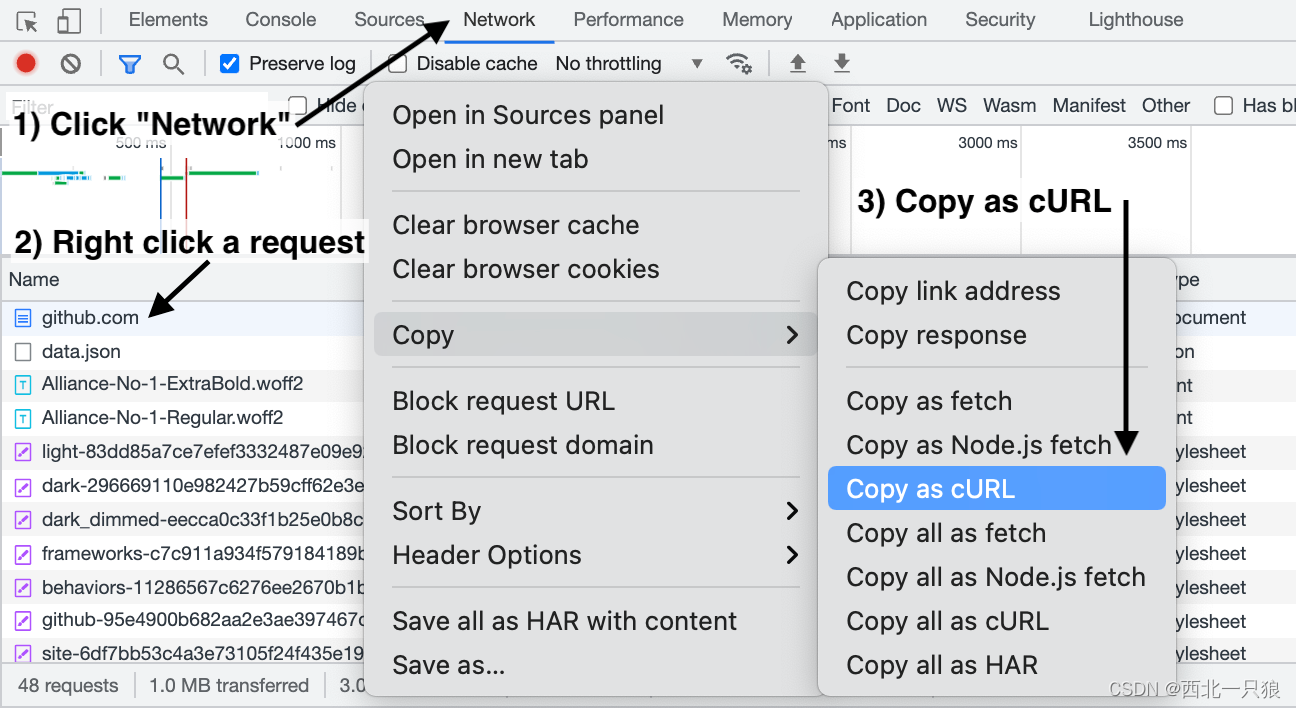
浏览器抓包,修改参数上报。
前端无限断点调试。
抓包替换JS。
Convert curl commands to Python, JavaScript, PHP, R, Go, Rust, Elixir, Java, MATLAB, Ansible URI, Strest, Dart or JSON
概述:Metabase可以帮助你把数据库中的数据更好的呈现给更多人,数据分析人员通过建立一个”查询“(Metabase中定义为Question)来提炼数据,再通过仪表盘(Dashboards)来组合展示给公司成员.
优点:
1.开源免费
2.工具轻量、安装依赖的环境简单、配置简单清楚
3.容易上手,操作门槛低,不会sql语句也能使用
4.支持对外共享,权限控制
5.Question可以便捷地创建图表,Dashboards界面整洁美观
缺点:
1.Question每次只能对数据库中的一张表进行查询,切换数据表已有的查询选项会重置
2.填写了sql语句的sql查询(Native query)模式不能转到点选查询(Custom)模式
MapReduce的编程模型的原理是:利用一个输入key/value对集合来产生一个输出的key/value对集合。MapReduce库的用户用两个函数表达这个计算:Map和Reduce。用户自定义的Map函数接受一个输入的key/value对值,然后产生一个中间key/value对值的集合。MapReduce库把所有具有相同中间key值的中间value值集合在一起后传递给Reduce函数。用户自定义的Reduce函数接受一个中间key的值和相关的一个value值的集合。Reduce函数合并这些value值,形成一个较小的value值的集合。
通过将Map调用的输入数据自动分割为M个数据片段的集合,Map调用被分布到多台机器上执行。输入的数据片段能够在不同的机器上并行处理。使用分区函数将Map调用产生的中间key值分成R个不同分区(例如,hash(key) mod R),Reduce调用也被分布到多台机器上执行。分区数量(R)和分区函数由用户来指定。
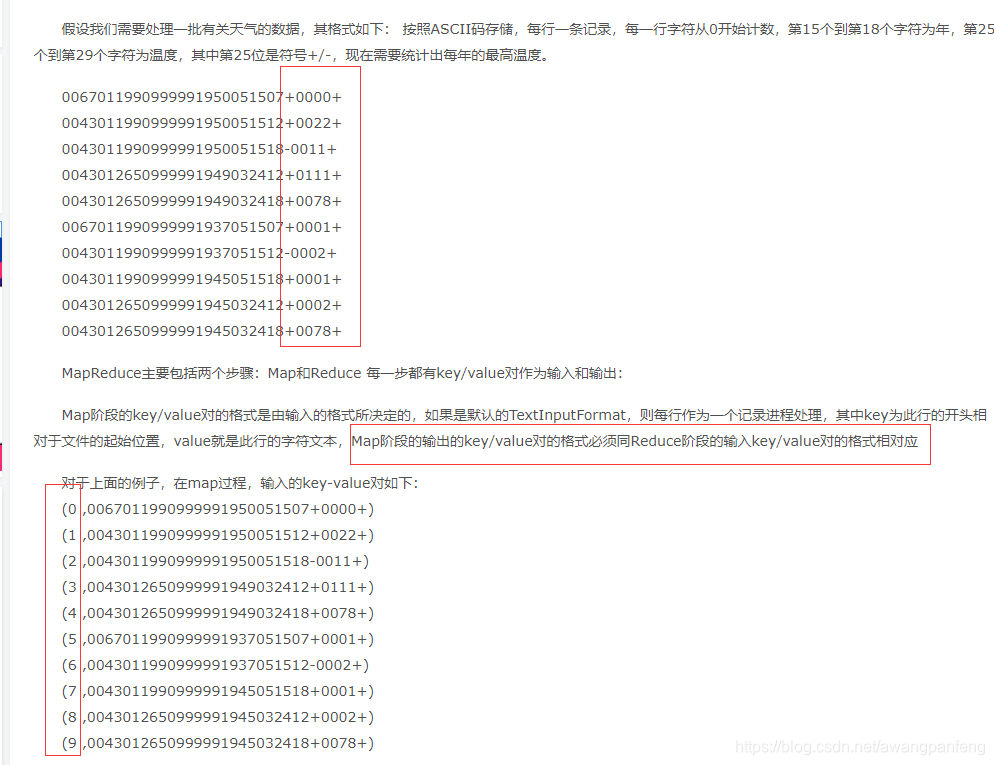
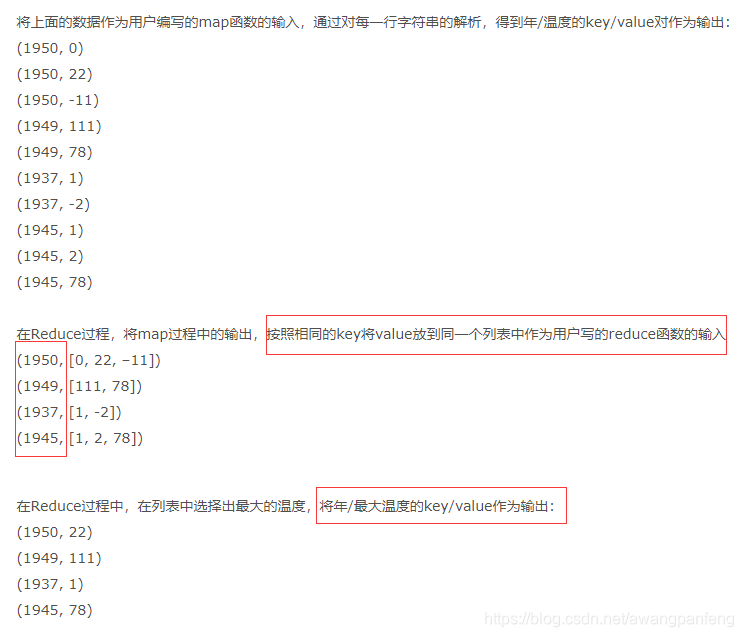
Map Demo
1 | public class MaxTemperatureMapper |
Reduce Demo
1 | public class MaxTemperatureReducer |
setup()
此方法被MapReduce框架仅且执行一次,在执行Map任务前,进行相关变量或者资源的集中初始化工作。若是将资源初始化工作放在方法map()中,导致Mapper任务在解析每一行输入时都会进行资源初始化工作,导致重复,程序运行效率不高!
go 调用 c/c++ 函数的实现方式有:
1、直接嵌套在go文件中使用,最简单直观的;
2、导入动态库 .so 或 dll 的形式,最安全但是很不爽也比较慢的;
3、直接引用 c/c++ 文件的形式,层次分明,容易随时修改看结果的;
(1)直接嵌套在go文件:
1 | package main |
但凡要引用与 c/c++ 相关的内容,写到 go 文件的头部注释里面;
嵌套的 c/c++ 代码必须符合其语法,不与 go 一样;
import “C” 这句话要紧随,注释后,不要换行,否则报错;
go 代码中调用 c/c++ 的格式是: C.xxx(),例如 C.add(2, 1);
直接上代码:
1 | b := buf.Bytes() |
背景
在SageMaker中使用wide and deep模型进行训练:
使用的TF2.X + tf.keras + tf.feature_column API。
优化前利用mirrostrategy distributed策略单机多卡训练超过26个小时。
痛点和诉求:
提升训练速度。
训练速度优化思路
从GPU使用率和CPU使用率入手:
GPU使用率很低(没有喂饱GPU)
CPU准备一个batch的数据相对于GPU(们)计算一个batch的数据太慢吗?
CPU准备一个batch的数据真的比较慢
CPU如何准备一个batch的数据
Data input pipeline是否足够优化
数据的预处理操作是在CPU还是GPU上做?
CPU准备一个batch不慢,GPU算的太快
Batch size太小吗?
模型结构太简单?
GPU之间是否需要协作?协作是否低效?
由于多卡训练协作引入的开销
GPU使用率挺高(营养过剩就一定会快吗?)
不同的模型可能都能让可见的GPU使用率比较高,但是用的GPU的tensor core和cuda core的数量很可能是不一样的。
从具体框架的API和代码入手:
框架的版本和使用了框架的什么feature?
TF1.X vs TF2.X?
Enable eager or disable eager?
多卡的训练方式是什么?
框架自带的多卡训练方式?
和第三方集成的多卡训练方式?
一行一行的review的代码
是否有耗时的操作其实没有必要?
是框架训练一个模型主流的代码调用形式吗?
Aerospike是一个高性能的分布式Key-Value NoSQL数据库,可基于行随机存取,索引存放在内存中。数据存取可以在内存中或者SSD。一个典型应用是广告业务。作为服务器端的cookie存储来使用,这种情况对写入性能要求比较高。
Aerospike是一个分布式,高可用的 K-V类型的Nosql数据库。提供类似传统数据库的ACID操作。
Aerospike最大的卖点就是可以存储在SSD上,并且保证和redis相同的查询性能。AS内部在访问SSD屏蔽了文件系统层级,直接访问地址,保证了数据的读取速度。 AS同时支持二级索引与聚合,支持简单的sql操作,相比于其他nosql数据库,有一定优势。
一个namespace包含记录(records),索引(indexes )及策略(policies)。
Set 存储于namespace,是一个逻辑分区,类比于传统数据库的表。set的存储策略继承自namespace,也可以为set设置单独的存储策略。
Records 类比于传统数据库的行,包含key,Bins(value),和Metadata(元数据)。key全局唯一,作为K-V数据库一般也是通过key去查询。Bins相当于列,存储具体的数据。元数据存储一些基本信息,例如TTL等。
特点:
键值存储, 内存 + 闪存(SSD) 存储数据,官方承诺查询 速度99% 达到1ms 低延迟和高吞吐量而闻名,已经用于许多大型的、要求堪称苛刻的实时平台
数据结构相对简单(意思是说没有REDIS丰富)
AerospikeDB是多线程的,而Redis是单线程的
可以把索引放在内存,数据放在SSD。
与纯内存数据库(如REDIS,SSDB)对比,扩展上性价比会高些(SSD的价格还是比内存便宜的)
支持跨机房(企业版)
1 | //连接 |

最近庆余年电视剧很火,前东家不厚道,我已经办理了包年的会员,还要花钱,不能忍。网上看到了很多链接,两周前已经看完了,等第二季咯。如果有需要讨论剧情的,欢迎留言哈。。。。
以下是链接,无需安装app,直接观看即可,安全放心,童叟无欺。就从39集开始吧,附件中是所有的链接,稍后上传。
NO.39.http://youku.cdn4-okzy.com/share/c5bbd980e5ab2c17413ec02bd757a9e5
NO.40.http://youku.cdn7-okzy.com/share/bb1d545891bbbebcf457ed1cad5394f8
NO.41.http://youku.cdn7-okzy.com/share/5f9ce39aec46f3e8e8aebbc722d8ceeb
NO.42.http://iqiyi.com-ok-iqiyi.com/share/c4b108f53550f1d5967305a9a8140ddd
NO.43.http://iqiyi.com-ok-iqiyi.com/share/c1399f2eb50e562b9e0f3778c16fd7a3
NO.44.http://youku.cdn4-okzy.com/share/2e1b24a664f5e9c18f407b2f9c73e821
NO.45.http://youku.cdn4-okzy.com/share/86a1793f65aeef4aeef4b479fc9b2bca
NO.46.http://youku.cdn6-okzy.com/share/7a951116de2a4c23c74733d76046a5b4
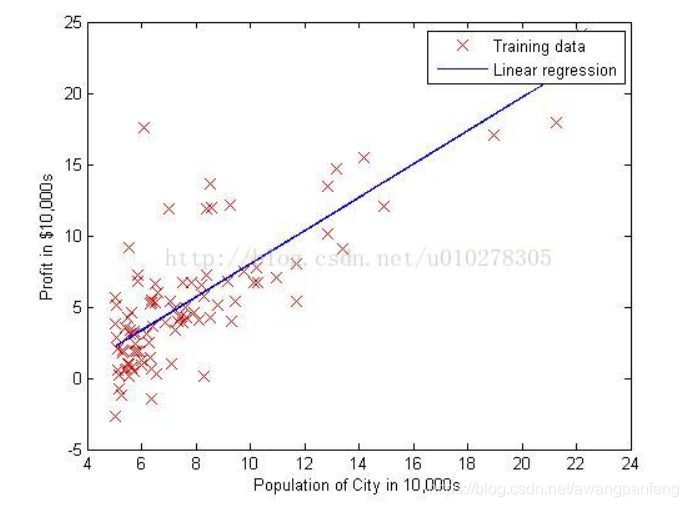
线性回归用一个线性函数对提供的已知数据进行拟合,得到一个线性函数,使这个函数满足我们的要求(如具有最小偏差、平方差等等),之后我们可以利用这个函数,对给定的输入进行预测。
假设最终得到的假设函数具有如下形式:
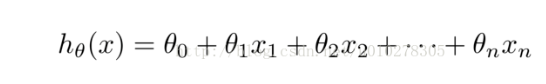
其中,x是输入,theta是要求的参数。
为了使得代价函数具有最小值,需要求得代价函数关于参量theta的导数:
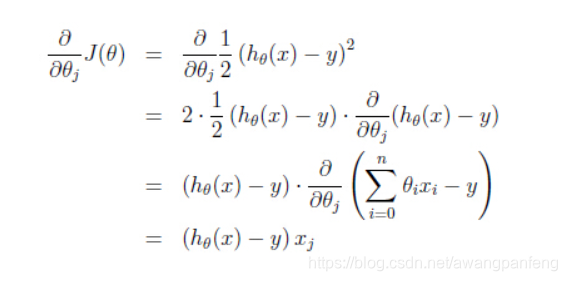

什么是逻辑回归?逻辑回归的模型是一个非线性模型,sigmoid函数,又称逻辑回归函数。但是它本质上又是一个线性回归模型,逻辑回归是以线性回归为理论支持的。只不过,线性模型,无法做到sigmoid的非线性形式,sigmoid可以轻松处理0/1分类问题。逻辑回归虽然名字里带“回归”,但是它实际上是一种分类方法,主要用于两分类问题(即输出只有两种,分别代表两个类别),函数形式为:
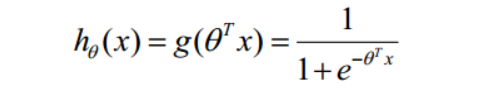
google-perftool,它是由google开发的用来分析C/C++程序性能的一套工具,这里的性能分析主要包括内存和CPU两个方面,内存分析使用google-perftool所提供的tcmalloc,CPU分析使用它所提供的profiler。下面先分别介绍一下tcmalloc和profiler,然后再给出一些使用的例子,及一些使用时的注意事项.
tcmalloc的全称是thread cache malloc,顾名思义,它是带有thread cache的内存管理工具,具体的实现细节这里不做过多的介绍,感兴趣的朋友可以参考google官方提供的文档,或者阅读源码。这里需要注明一下tcmalloc的一些优点,和它所提供的一些分析程序内存使用的一些功能。
tcmalloc的主要优点有两个方面,一个是内存allocate/deallocate的速度,通常情况下它的速度比glibc所提供的malloc要快;另一个方面是小内存(< =32K)的管理,它的小内存是在thread cache里面管理的,一方面减少了加锁的开销,另一方面用来表示小内存所用的额外的空间也比较小,比较节省空间。因此,对于多线程下,经常小内存的allocation/deallocation的程序(尤其多线程下使用STL比较多的程序),可以尝试使用一下tcmalloc。
除了在allocate/deallocate内存时的优化外,tcmalloc还提供了heapcheck和heapprofile的功能。heapcheck主要被用来检查程序中是否有内存泄露,在哪里泄露。相信内存泄露这个话题,永远是让所有C/C++程序都非常蛋疼的问题,有了tcmalloc的帮助,也许一切会变得简单一些,会有点事半功倍的效果。tcmalloc另外一个功能是heapprofile。先来说一下profile这个词,它的本意是“描绘…轮廓”,我一直觉得这个词是一个很伟大的词,用在sns中,它表示用来描绘用户的那些特征、属性,也有叫用户画像的。用在这里呢,heapprofile,顾名思义,它就是描绘程序的heap轮廓,通过这样一个过程,我们就能知道,程序的heap里在每一时刻都有些啥东东。有了profile的结果,它可以帮助我们定位内存泄露,帮助我们发现一些频繁allocate内存的地方,以此来做一些优化。
profiler,是由google-perftool所提供的用来做cpu-profile的工具,相信通过上面的介绍,大家对profile这个词已经不再陌生。Cpu-profile,它的主要功能就是通过采样的方式,给程序中cpu的使用情况进行“画像”,通过它所输出的结果,我们可以对程序中各个函数耗时情况一目了然。在对程序做性能优化的时候,这个是很重要的,先把最耗时的若干个操作优化好,程序的整体性能提升应该十分明显,这也是做性能优化的一个最为基本的原则—先优化最耗时的。
关于google-perftool的使用,总体上来讲有以下三种方式:
(1)直接调用提供的api:这种方式比较适用于对于程序的某个局部来做分析的情况,直接在要做分析的局部调用相关的api即可。