1、join操作
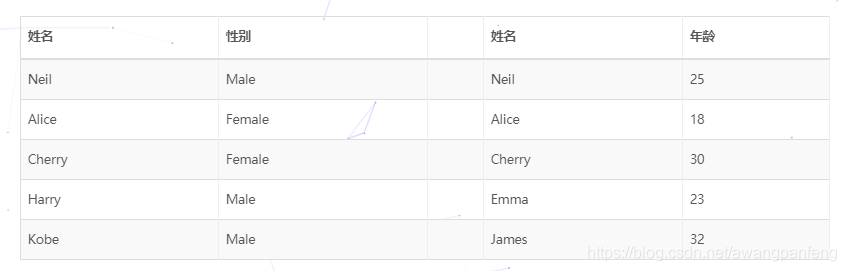
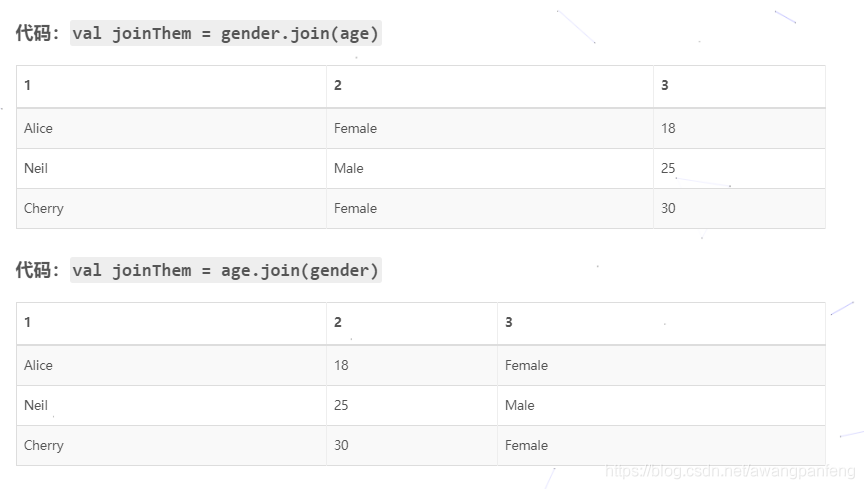
join操作是在特征提取过程中非常常见的一种需求,从多个不同文件完成了特征提取之后,通过join合并为一个完整的特征,可以方便进行接下来的模型训练、预测等其它操作。首先我们准备两份简单的数据,gender和age,其中两张表中的前3条有相同的姓名,后两条不同。
2、union
就是将两个RDD进行合并,不去重。
3、map
map是对RDD中的每个元素都执行一个指定的函数来产生一个新的RDD。任何原RDD中的元素在新RDD中都有且只有一个元素与之对应。
1 | scala> val a = sc.parallelize(1 to 9, 3) |
4、parallelize
创建出一个可以被并行操作的分布式数据集。
1 | data = [1, 2, 3, 4, 5] |
一旦分布式数据集(distData)被创建好,它们将可以被并行操作。例如,我们可以调用distData.reduce(lambda a, b: a + b)来将数组的元素相加。
5、reduceByKey
reduceByKey将RDD中所有K,V对中,K值相同的V进行合并,而这个合并,仅仅根据用户传入的函数来进行。参数是Value.
1 | scala> byKey.foreach(println) |
6、filter
过滤数据
1 | val rdd = sc.parallelize(Seq(("a",1), ("a",2), ("b",2), ("b",3), ("c",1))) |
整数类型数据的过滤
rdd.filter(_._2==2)
7、groupBy
groupBy(function) function返回key,传入的RDD的各个元素根据这个key进行分组
1 | val a = sc.parallelize(1 to 9, 3) |
8、groupByKey( )
1 | val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "spider", "eagle"), 2) |
9、keyBy
为各个元素,按指定的函数生成key,形成key-value的RDD。
1 | scala> val a = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), 3) |
10、lookup
从key-value型的RDD中,筛选出指定的key集合。返回的是Scala的sequence。
1 | val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", "eagle"), 2) |