Ray Ray是一个用于并行和分布式 Python 的开源项目,当我们将应用程序迁移到分布式设置时,传统编程概念会发生变化。比如用于模型培训的 TensorFlow、用于数据处理和 SQL 的 Spark 以及用于流处理的 Flink。这些工具提供更高层次的抽象,如神经网络、数据集和流 。但是,由于它们与串行编程所使用的抽象不同,因此必须重新编写应用程序 以利用它们。
Ray占据了一个独特的中间地带 。而不是引入新的概念。Ray 获取函数和类的现有概念,并将它们作为任务和参与者转换为分布式设置。这种 API 选择允许串行应用程序并行化,而不需要进行重大修改 。
Ray 可以用来在多个核心或机器上扩展 Python 应用。它有几个主要的优点,包括:
简单性:你可以扩展你的 Python 应用,而不需要重写,同样的代码可以在一台机器或多台机器上运行。
稳健性:应用程序可以优雅地处理机器故障和进程抢占。
性能:任务以毫秒级的延迟运行,可扩展到数万个内核,并以最小的序列化开销处理数值数据。
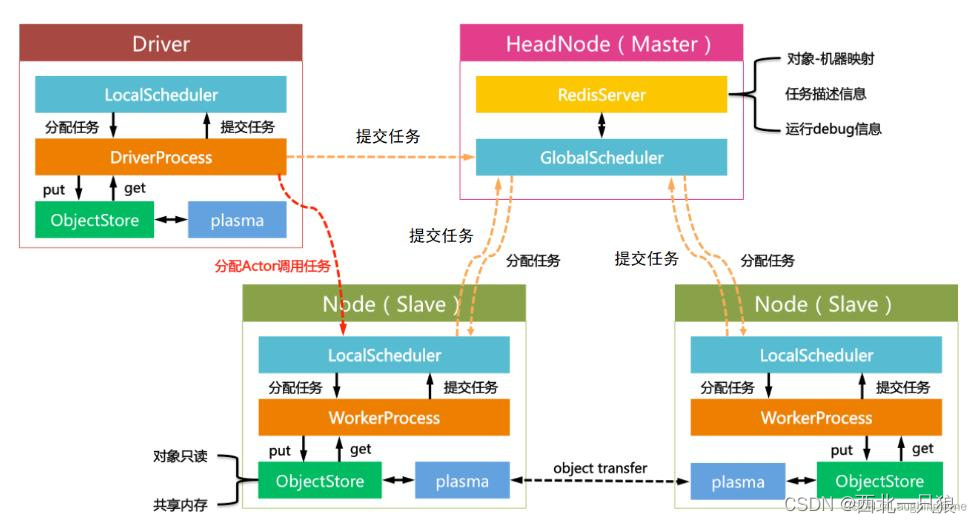
作为分布式计算系统,Ray仍旧遵循了典型的Master-Slave的设计:Master负责全局协调和状态维护,Slave执行分布式计算任务。不过和传统的分布式计算系统不同的是,Ray使用了混合任务调度 的思路。
GlobalScheduler :Master上启动了一个全局调度器,用于接收本地调度器提交的任务,并将任务分发给合适的本地任务调度器执行。RedisServer :Master上启动了一到多个RedisServer用于保存分布式任务的状态信息(ControlState),包括对象机器的映射、任务描述、任务debug信息等。LocalScheduler :每个Slave上启动了一个本地调度器,用于提交任务到全局调度器,以及分配任务给当前机器的Worker进程。Worker :每个Slave上可以启动多个Worker进程执行分布式任务,并将计算结果存储到ObjectStore。ObjectStore :每个Slave上启动了一个ObjectStore存储只读数据对象,Worker可以通过共享内存的方式访问这些对象数据,这样可以有效地减少内存拷贝和对象序列化成本。ObjectStore底层由Apache Arrow实现。Plasma :每个Slave上的ObjectStore都由一个名为Plasma的对象管理器进行管理,它可以在Worker访问本地ObjectStore上不存在的远程数据对象时,主动拉取其它Slave上的对象数据到当前机器
Ray的任务也是通过类似Spark 中Driver的概念的方式进行提交 的,有所不同的是:
Spark的Driver提交的是任务DAG,一旦提交则不可更改。
而Ray提交的是更细粒度的remote function,任务DAG依赖关系由函数依赖关系自由定制。
安装 1 2 pip install --upgrade pip pip install ray == 1.6.0
使用 1、ray.init() ,类似sparkSession
如果是直连已有的Ray集群,只需要指定RedisServer的地址即可。
1 ray.init(redis_address="<redis-address>" )
本地启动Ray时,可以看到Ray的WebUI的访问地址
2、ray.put(), 类似Spark RDD并行化
使用ray.put()可以将Python对象存入本地ObjectStore,并且异步返回一个唯一的ObjectID。通过该ID,Ray可以访问集群中任一个节点上的对象
1 2 3 4 5 6 7 8 9 10 11 12 @ray.remote def f (x ): pass x = "hello" [f.remote(x) for _ in range (10 )] x_id = ray.put(x) [f.remote(x_id) for _ in range (10 )]
3、ray.get()
使用ray.get()可以通过ObjectID获取ObjectStore内的对象并将之转换为Python对象。对于数组类型的对象,Ray使用共享内存机制减少数据的拷贝成本。而对于其它对象则需要将数据从ObjectStore拷贝到进程的堆内存中。
如果调用ray.get()操作时,对象尚未创建好,则get操作会阻塞,直到对象创建完成后返回。get操作的关键流程如下:
Driver或者Worker进程首先到ObjectStore内请求ObjectID对应的对象数据。
如果本地ObjectStore没有对应的对象数据,本地对象管理器Plasma会检查Master上的对象表查看对象是否存储其它节点的ObjectStore。
如果对象数据在其它节点的ObjectStore内,Plasma会发送网络请求将对象数据拉到本地ObjectStore。
如果对象数据还没有创建好,Master会在对象创建完成后通知请求的Plasma读取。
如果对象数据已经被所有的ObjectStore移除(被LRU策略删除),本地调度器会根据任务血缘关系执行对象的重新创建工作。
一旦对象数据在本地ObjectStore可用,Driver或者Worker进程会通过共享内存的方式直接将对象内存区域映射到自己的进程地址空间中,并反序列化为Python对象。
ray.get()可以一次性读取多个对象的数据
1 2 result_ids = [ray.put(i) for i in range (10 )] ray.get(result_ids)
4、@ray.remote
Ray中使用注解@ray.remote可以声明一个remote function。remote函数时Ray的基本任务调度单元,remote函数定义后会立即被序列化存储到RedisServer中,并且分配了一个唯一的ID,这样就保证了集群的所有节点都可以看到这个函数的定义。这样对remote函数定义有了一个潜在的要求,即remote函数内如果调用了其它的用户函数,则必须提前定义 ,否则remote函数无法找到对应的函数定义内容。
调用remote函数的关键流程如下:
调用remote函数时,首先会创建一个任务对象,它包含了函数的ID、参数的ID或者值(Python的基本对象直接传值,复杂对象会先通过ray.put()操作存入ObjectStore然后返回ObjectID)、函数返回值对象的ID。
任务对象被发送到本地调度器。
本地调度器决定任务对象是在本地调度还是发送给全局调度器。如果任务对象的依赖(参数)在本地的ObejctStore已经存在且本地的CPU和GPU计算资源充足,那么本地调度器将任务分配给本地的WorkerProcess执行。否则,任务对象被发送给全局调度器并存储到任务表(TaskTable)中,全局调度器根据当前的任务状态信息决定将任务发给集群中的某一个本地调度器。
本地调度器收到任务对象后(来自本地的任务或者全局调度分配的任务),会将其放入一个任务队列中,等待计算资源和本地依赖满足后分配给WorkerProcess执行。
Worker收到任务对象后执行该任务,并将函数返回值存入ObjectStore,并更新Master的对象表(ObjectTable)信息。
@ray.remote注解有一个参数num_return_vals用于声明remote函数的返回值个数,基于此实现remote函数的多返回值机制
1 2 3 4 5 6 7 @ray.remote(num_return_vals=2 ) def f (): return 1 , 2 x_id, y_id = f.remote() ray.get(x_id) ray.get(y_id)
@ray.remote注解的另一个参数num_gpus可以为任务指定GPU的资源
1 2 3 @ray.remote(num_gpus=1 ) def gpu_method (): return "This function is allowed to use GPUs {}." .format (ray.get_gpu_ids())
5、ray.wait()
ray.wait()操作支持批量的任务等待,基于此可以实现一次性获取多个ObjectID对应的数据。
1 2 3 4 results = [f.remote(i) for i in range (5 )] ready_ids, remaining_ids = ray.wait(results, num_returns=4 , timeout=2500 )
上述例子中,results包含了5个ObjectID,使用ray.wait操作可以一直等待有4个任务完成后返回,并将完成的数据对象放在第一个list类型返回值内,未完成的ObjectID放在第二个list返回值内。如果设置了超时时间,那么在超时时间结束后仍未等到预期的返回值个数,则已超时完成时的返回值为准。
6、ray.error_info()
使用ray.error_info()可以获取任务执行时产生的错误信息。
7、Actor
Ray的remote函数只能处理无状态的计算需求,有状态的计算需求需要使用Ray的Actor实现。在Python的class定义前使用@ray.remote可以声明Actor 。
1 2 3 4 5 6 7 8 @ray.remote class Counter (object ): def __init__ (self ): self .value = 0 def increment (self ): self .value += 1 return self .value
使用如下方式创建Actor对象。
1 2 a1 = Counter.remote() a2 = Counter.remote()
调用Actor对象的方法使用Actor
1 2 a1.increment.remote() a2.increment.remote()
调用Actor对象的方法的流程为:
首先创建一个任务。
该任务被Driver直接分配到创建该Actor对应的本地执行器执行,这个操作绕开了全局调度器(Worker是否也可以使用Actor直接分配任务尚存疑问)。
返回Actor方法调用结果的ObjectID。
为了保证Actor状态的一致性,对同一个Actor的方法调用是串行执行的 。
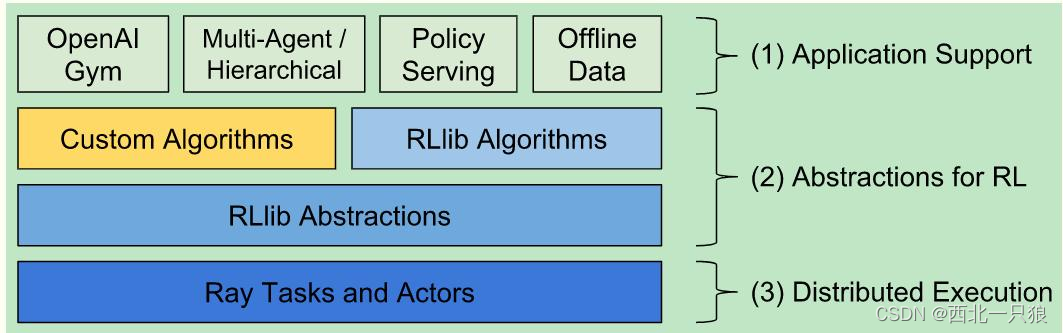
RLlib RLlib是一个用于强化学习的开源库,它为各种应用程序提供了高可伸缩性(Scalable Reinforcement Learning)和统一API。RLlib本身支持TensorFlow、TensorFlow Eager和PyTorch,但它的大多数内部内容是框架无关的。RLlib之于Ray就如同MLlib之于Spark :
1 2 3 from ray importtunefrom ray.rllib.agents.ppo importPPOTrainertune.run(PPOTrainer, config={"env" : "CartPole-v0" })
上面三行代码就可以训练一个玩平衡杆游戏的智能体
最底层的分布式计算任务是由Ray引擎支撑的。倒数第二层表明RLlib是对特定的强化学习任务进行的抽象。第二层表示面向开发者,我们可以自定义算法。最顶层是RLlib对一些应用的支持,比如:可以让智能体在离线的数据、Gym或者Unit3d的环境中进行交互等等
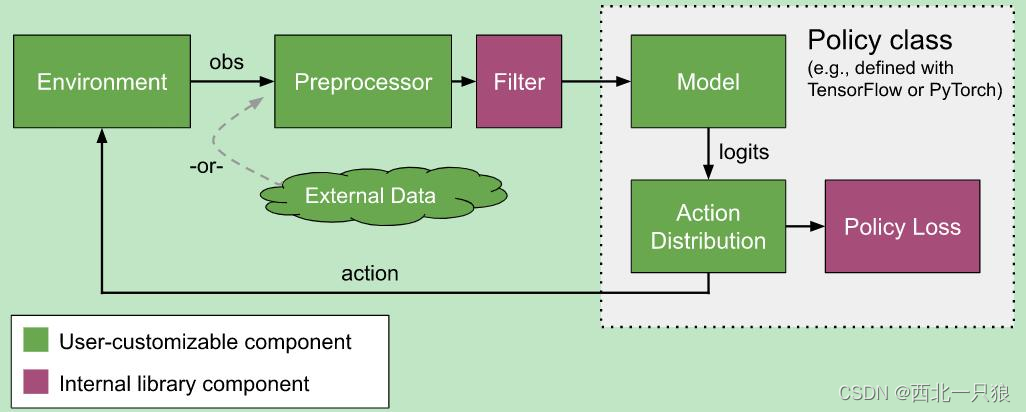
Policies ,策略是RLlib中的核心概念.policies是定义agent 如何在环境中工作的Python类. Rollout workers查询策略以确定agent 的动作。在gym 中,只有一个agent 和policy。在vector envs 中,策略推理是针对多个代理的,在多代理中,可能有多个策略,每个策略控制一个或多个代理:
Training 每个策略都定义了一个learn_on_batch()方法,该方法根据输入的样例批处理改进策略。对于TF和Torch策略,这是使用一个损失函数来实现的,该函数以样本批张量作为输入,并输出一个标量损失。
RLlib Trainer类协调分布式工作流(启动rollouts worker和策略优化)。它们利用Ray并行迭代器来实现所需的计算模式。下面的图显示了同步采样,这是这些模式中最简单的:
Trainer将数据广播给所有Workers,由他们与环境交互产生数据,经过抽样的方式返回Trainer进行训练。
RLlib使用Ray actor将训练从单个核扩展到集群中的数千个核。可以通过更改num_workers参数来配置用于培训的并行性。
RLlib几乎提供了自定义训练过程中所有方面的方法,包括环境(environment、神经网络模型(neural network model)、行动分布(action distribution)和策略定义(policy definitions):
超参数搜索库 Tune:
Ray Tune是一个用来实验执行和超参数调优的Python包,其中集成了网格搜索、随机搜索、贝叶斯优化搜索(BayesOptSearch)等搜索算法以及Optuna, Hyperopt等优化工具。Ray Tune调参的模型可以是基于PyTorch, XGBoost, TensorFlow或Keras等框架构建的模型。
安装
使用tune,搜索lr的最佳超参值:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import torch.optim as optimfrom ray import tunefrom ray.tune.examples.mnist_pytorch import get_data_loaders, ConvNet, train, testdef train_mnist (config ): train_loader, test_loader = get_data_loaders() model = ConvNet() optimizer = optim.SGD(model.parameters(), lr=config["lr" ]) for i in range (30 ): train(model, optimizer, train_loader) acc = test(model, test_loader) tune.track.log(mean_accuracy=acc) analysis = tune.run( train_mnist, num_samples=10 , config={"lr" : tune.grid_search([0.001 , 0.01 , 0.1 ])}) print ("Best config: " , analysis.get_best_config(metric="mean_accuracy" ))df = analysis.dataframe()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 https://github.com/IntelLabs/coach https://github.com/cjy1992/gym-carla https://github.com/LovelyBuggies/sumo-gym https://github.com/SaloniDash7/gym-sumo https://github.com/LucasAlegre/sumo-rl pip install git+https://github.com/DLR-RM/stable-baselines3@feat/gymnasium-support pip install git+https://github.com/Stable-Baselines-Team/stable-baselines3-contrib@feat/gymnasium-support pip install git+https://github.com/DLR-RM/stable-baselines3@feat/gymnasium-support pip install git+https://github.com/Stable-Baselines-Team/stable-baselines3-contrib@feat/gymnasium-support
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 import gymimport matplotlib.pyplot as pltimport numpy as npfrom gym import spacesfrom imitation.algorithms.adversarial.gail import GAILfrom imitation.data import rolloutfrom imitation.data.types import Transitionsfrom imitation.data.wrappers import RolloutInfoWrapperfrom imitation.rewards.reward_nets import BasicRewardNetfrom imitation.util import logger as imit_loggerfrom imitation.util.networks import RunningNormfrom stable_baselines3 import PPO from stable_baselines3.common.env_checker import check_envfrom stable_baselines3.common.env_util import make_vec_envfrom stable_baselines3.common.evaluation import evaluate_policyfrom stable_baselines3.common.vec_env import DummyVecEnvfrom stable_baselines3.ppo import MlpPolicyimport torch as thlog_dir = "./tensorboard/Custom-Env" class CustomEnv (gym.Env): def __init__ (self, max_steps=8 ): super ().__init__() self .observation_space = spaces.Box(low=-1 , high=1 , shape=(2 ,), dtype=np.float32) self .action_space = spaces.Box(low=-1 , high=1 , shape=(2 ,), dtype=np.float32) self .max_steps = max_steps self .n_steps = 0 def reset (self ): self .n_steps = 0 return self .observation_space.sample() def step (self, action ): self .n_steps += 1 done = False reward = 0.0 if self .n_steps >= self .max_steps: reward = 1.0 done = True return self .observation_space.sample(), reward, done, {} def load_expert_transitions (env, length ): obs = np.array([env.observation_space.sample() for _ in range (length)]) acts = np.array([env.action_space.sample() for _ in range (length)]) infos = np.array([{i: i} for i in range (length)]) next_obs = np.array([env.observation_space.sample() for _ in range (length)]) dones = np.zeros(length, dtype=bool ) return Transitions(obs=obs, acts=acts, infos=infos, next_obs=next_obs, dones=dones) if __name__ == "__main__" : env = CustomEnv() if check_env(env): print ("The Custom environment check done" ) device = th.device("cuda" if th.cuda.is_available() else "cpu" ) print (device) transitions = sample_expert_transitions() venv = make_vec_env(lambda : env) learner = PPO( env=venv, policy=MlpPolicy, batch_size=64 , ent_coef=0.0 , learning_rate=0.0003 , n_epochs=10 , device=device, ) reward_net = BasicRewardNet( venv.observation_space, venv.action_space, normalize_input_layer=RunningNorm ) custom_logger = imit_logger.configure( folder=log_dir, format_strs=["tensorboard" , "stdout" ], ) gail_trainer = GAIL( demonstrations=transitions, demo_batch_size=2 , gen_replay_buffer_capacity=2048 , n_disc_updates_per_round=4 , venv=venv, gen_algo=learner, reward_net=reward_net, log_dir=log_dir, init_tensorboard=False , init_tensorboard_graph=False , custom_logger=custom_logger ) learner_rewards_before_training, _ = evaluate_policy( learner, venv, 10 , return_episode_rewards=True ) gail_trainer.train(20000 ) learner_rewards_after_training, _ = evaluate_policy( learner, venv, 10 , return_episode_rewards=True ) print (np.mean(learner_rewards_after_training)) print (np.mean(learner_rewards_before_training)) plt.hist( [learner_rewards_before_training, learner_rewards_after_training], label=["untrained" , "trained" ], ) plt.legend() plt.show() learner.save("./gail.model" ) model = learner.load("./gail.model" ) print (model.predict(env.reset(), deterministic=True ))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 self .simulation = TraCISimulation(self ) self .network = TraCIKernelNetwork(self , sim_params) self .vehicle = TraCIVehicle(self , sim_params) tc.VAR_LANE_INDEX, tc.VAR_LANEPOSITION, tc.VAR_ROAD_ID, tc.VAR_SPEED, tc.VAR_EDGES, tc.VAR_POSITION, tc.VAR_ANGLE, tc.VAR_SPEED_WITHOUT_TRACI, tc.VAR_FUELCONSUMPTION, tc.VAR_DISTANCE self .traffic_light = TraCITrafficLight(self ) step里面执行仿真 以及update https://github.com/zbzhu99/NGSIM_Imitation https://github.com/wsjeon/multiagent-gail/tree/e7dd75f0dee17e33e55d7f4e24d40649fd648cf3