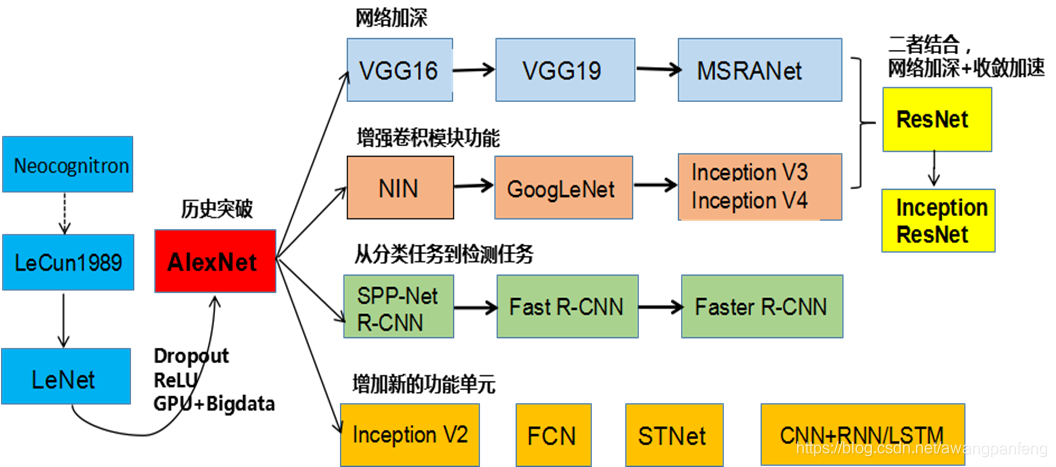
日常生活中经常会碰到大额人民币因为保管不善而变成一堆烂钞,这种情况在偏远农村普遍存在。由于农村基层金融机构缺乏,农民通常将现钞保存在手上,经常遭到虫咬鼠啃、火烧水浸,辛苦得来的钱财成了一堆碎片。
若这些碎片拿到银行去兑换,依据相关规定,残币须拼出大于原图的 50%方允许兑换。用人工方法进行拼接,费时费力。因此,有必要开发一种机器方法对碎片进行自动拼接。要实现这种自动拼接,首先要找到人民币碎片在基准图上的位置,也就是要找到一种恰当的图像匹配方法。
一般而言,图像匹配的算法可分为两类:
(1)是基于图像灰度的匹配算法
(2)是基于图像特征的匹配算法
由于基于灰度的匹配算法计算量大,Barnea 于 1972 年提出序贯相似性算法———SSDA法,而 Wong 于 1978 年提分层序贯匹配算法以加快速度传统的基于灰度的匹配方法虽然在匹配精度,对噪声具有鲁棒性等方面具有优势,但对待匹配图像间的角度旋转敏感。当待配图像间存在相对的旋转角时,就会发生错误匹配。
为克服这一缺陷,本文提出了改进的sift算法,由于人民币碎片图像不可能与基准图保持平行关系,因此要想将基于灰度的匹配算法用于碎片图像匹配,基于特征的匹配算法,则是基于图像的边缘、特征点、纹理等特征,将图像的匹配转化为少量特征的匹配,从而可提高匹配速度。
SIFT算法,即Scale Invariant Feature Transform,是David G Lowe于2004年提出。它具有许多优良的特性:
1.不变性:对旋转、尺度缩放、亮度变化保持不变。
2.独特性:能在大量特征数据中进行快速、准确的匹配。