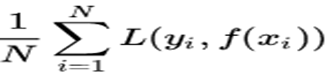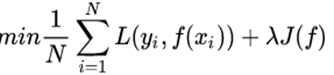生成式模型与判别式模型的对比:
这两种模型都能做分类和回归,生成式模型还可以生成样本。
从统计学的观点看,判别式模型是对条件概率P(Y|X)建模;
如果不从统计学的角度看,判别式模型也可以直接对决策函数比如线性回归或者决策边界比如SVM来建模。
生成式模型对联合概率P(X,Y)建模。
根据具体的实现可以得到P(X|Y),P(Y|X),P(X), P(Y),而不一定需要P(X,Y)的解析解。
生成式模型可以转化为判别式模型,但反过来不行。
生成式模型优点:
训练时收敛比较快,即当样本数量较多时,生成模型能更快地收敛于真实模型。
能够应对存在隐变量的情况,比如GMM就是含有隐变量的生成方法。
能够生成新的样本。
判别式模型优点:
节省计算资源,并且同样的模型效果情况下,需要的样本数量也少于生成模型。
模型一般要简单一些,模型性能往往较生成模型高。
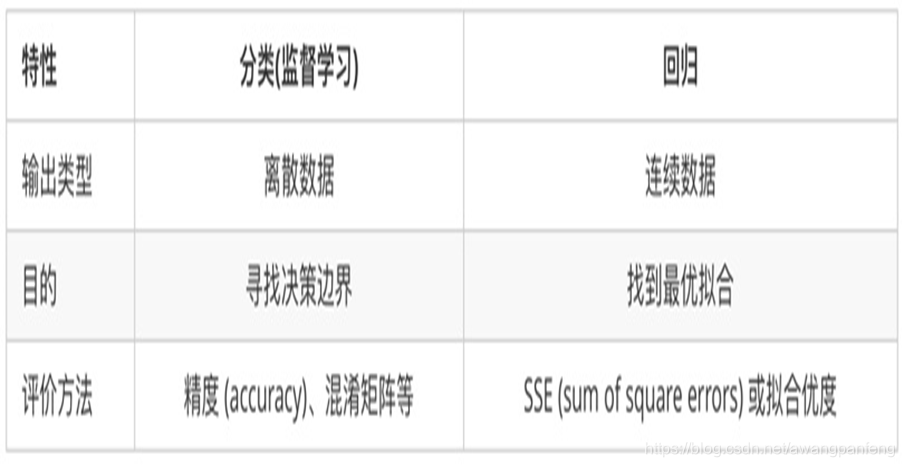
分类任务时,判别式模型与生成式模型的对比: